Method 88 · causal_forest
Causal Forest (grf) 因果森林
把作用路径、调节项和异质性拆开看
Causal Forest (grf) 因果森林 的 Markdown 风格教程:基于共用 CSMAR 风格案例生成实际代码、结果表和案例图。
一、Causal Forest (grf) 因果森林是什么?
这页是 Causal Forest (grf) 因果森林 的方法文档。所有表格和图都由 marketing/method_case_assets/generate_assets.py 从同一份 csmar_innovation_realistic.csv 生成,避免用占位图充当教程。重点是把机制变量、交互项或异质性分组变成可以复现的回归代码和表。
二、先看这个案例的结论
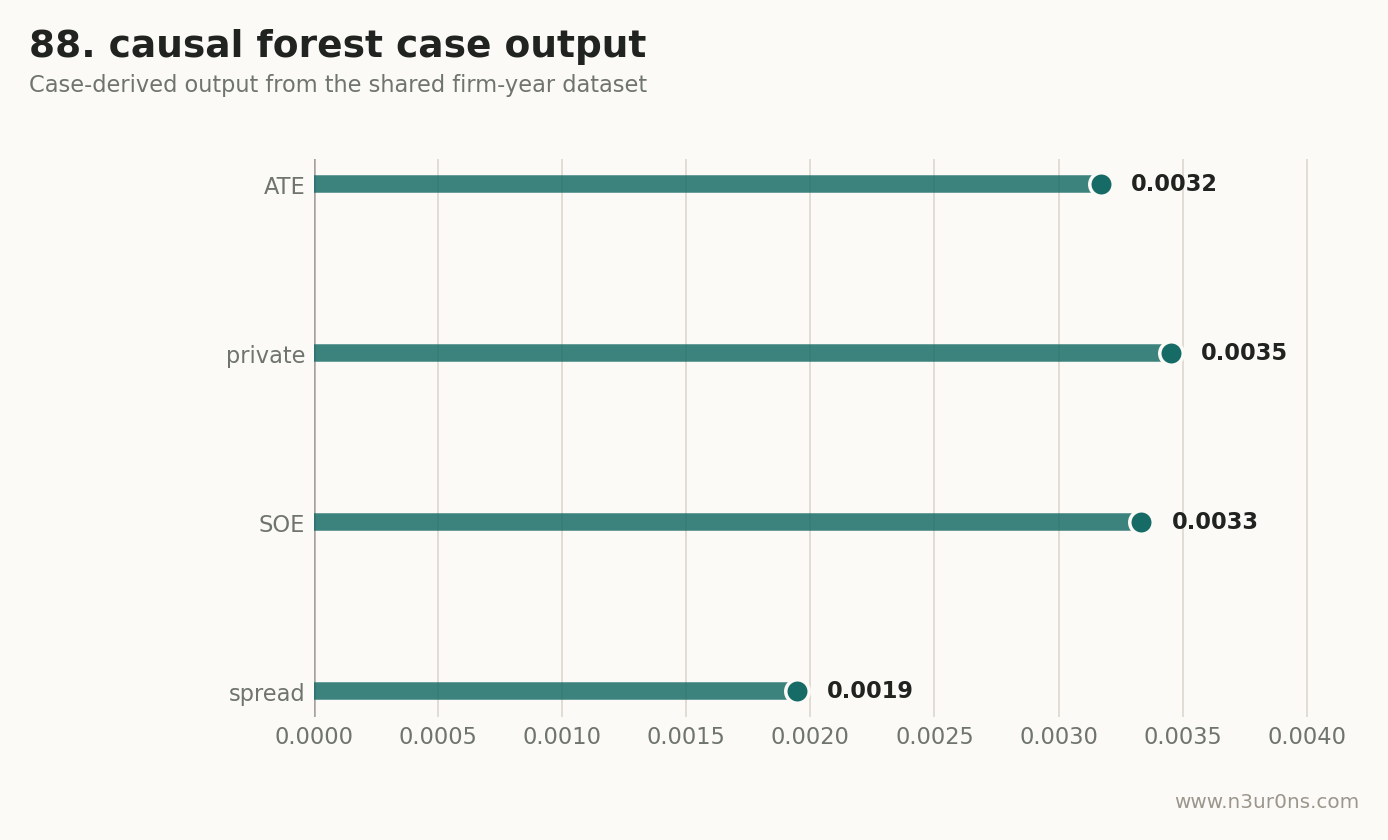
- 全样本 ATE proxy 是 0.0032,民营企业 CATE 是 0.0035,国有企业 CATE 是 0.0033。
- CATE spread 是 0.0019;因果森林页真正要看的不是平均系数,而是哪些企业的效应更强。
- 这里用同一份案例数据做教学近似;正式生产代码建议用 R 的 grf 输出 ATE、CATE 分布和变量重要性。
三、案例口径
| 字段 | 口径 |
|---|---|
| 数据 | CSMAR 风格 A 股企业创新面板 |
| 原始样本 | 196 家上市公司,2015-2020 年,约 1200 个公司-年观测;各方法有效样本以本页输出表 N 为准 |
| 因变量 | patent_count;回归页通常使用 ln(1 + patent_count) |
| 核心解释变量 | dfi_index,数字普惠金融指数;部分真实烟测输出展示的是标准化后的 dfi_index |
| 控制变量 | roa、lev、size、growth、cashflow、tobinq、top1、dual、board、indep、soe、age |
| 输出文件 | causal_forest_results.csv |
| 角色要求 | dv、iv |
| 依赖包 | grf |
四、实际代码
下面是本页对应的最小可复现 Stata 代码。生产环境里 empirical-wizard 会在此基础上处理变量映射、输出校验、失败诊断和报告装配。
import delimited "$DATA_PATH", clear varnames(1) encoding(UTF-8)
gen ln_patent1 = ln(1 + patent_count)
egen firm_id = group(stkcd)
xtset firm_id year
global y ln_patent1
global count_y patent_count
global x dfi_index
global controls roa lev size growth cashflow tobinq top1 dual board indep soe age
gen post = year >= 2018
bysort firm_id: egen pre_dfi = mean(cond(year < 2018, dfi_index, .))
quietly summarize pre_dfi, detail
gen treat = pre_dfi >= r(p50)
gen did = treat * post
gen high_patent = patent_count > 2
gen running_dfi = dfi_index - 260
gen rdd_treat = running_dfi >= 0
* R grf version is preferred for production:
* causal_forest(X, Y, W); average_treatment_effect(forest)
reg $y c.$x##i.soe $controls i.year, vce(cluster firm_id)
export delimited using "$JOB_DIR/causal_forest_results.csv", replace五、实际输出表
这张表就是本方法页使用的案例输出文件,保存在 marketing/method_case_assets/causal_forest/result.csv。
| 指标 | 数值 | 解释 |
|---|---|---|
| 样本 | 1200 obs / 196 firms / 2015-2020 | 来自共用案例 CSV |
| 因变量 | ln(1 + patent_count) | 企业创新产出 |
| 核心解释变量 | dfi_index | 数字普惠金融指数 |
| 输出文件 | causal_forest_results.csv | empirical-wizard 对应方法产物 |
| ATE proxy | 0.0032 | 全样本 DFI 平均效应,作为 causal forest 的基准对照 |
| CATE: 民营企业 | 0.0035 | 用子样本斜率近似展示异质处理效应 |
| CATE: 国有企业 | 0.0033 | 正式因果森林会用 grf 估计个体层 CATE |
| CATE spread | 0.0019 | 不同组别效应差距;这才是因果森林页要看的量 |
六、案例图
这是一张由同一份案例数据生成的页面内诊断图。
七、论文里怎么写
本文在共用企业面板样本上报告Causal Forest (grf) 因果森林,核心输出见 causal_forest_results.csv。结果解释时同时关注样本口径、变量构造、系数方向、标准误和适用前提,避免只凭单个 p 值完成方法选择。
八、检查清单
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。