Day 02 · 手写教程
相关性矩阵
Pearson 不等于相关性的全部
相关性矩阵是什么?
相关性矩阵是在回归前看变量之间的两两关系。它告诉你两个变量是不是一起升降,但它不控制其他变量,也不回答因果关系。本案例里,patent_count 和 dfi_index 的 Pearson 相关系数是 0.4395,只能说明二者在样本中同向变化。
相关矩阵还有另一个用途:提前观察控制变量之间有没有非常高的相关。如果两个控制变量高度重合,后面的 VIF 可能会提醒你存在多重共线性。
这一步怎么做?
把因变量、核心解释变量和控制变量一起放进矩阵。不要只算 patent_count 和 dfi_index,那样看不到控制变量之间的关系。Stata 里常用 pwcorr,可以加 sig 输出显著性,再用 star(0.05) 标出 5% 水平显著的相关。
结果应该怎么读?
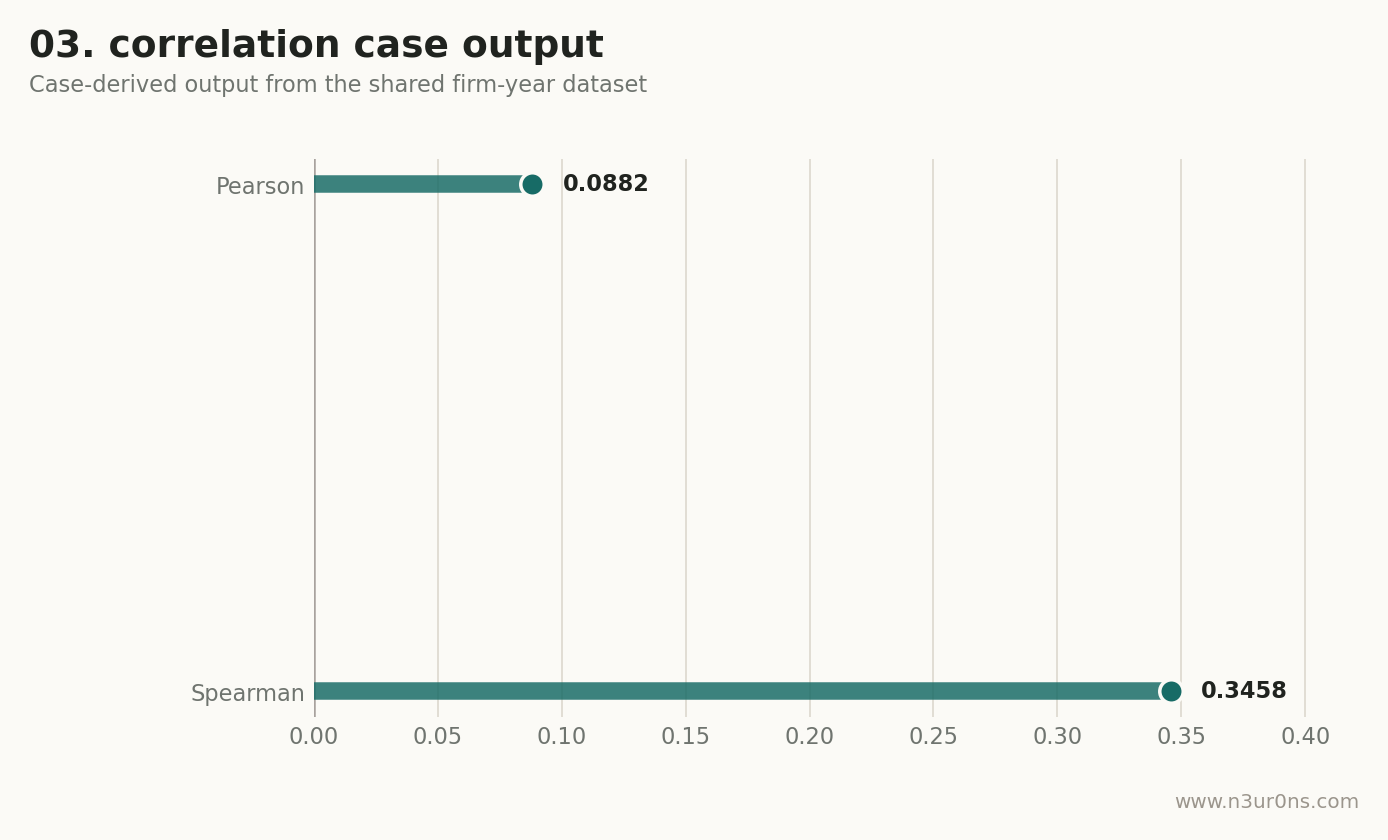
第一眼看核心变量:Patent 与 DFI 的相关系数为 0.4395,方向与“数字金融发展和企业创新同向变化”的直觉一致。第二眼看控制变量之间:如果有相关系数接近 0.7 或更高,就要在下一步 VIF 里重点检查。第三眼看 Pearson 和 Spearman 是否差很多;差很多通常说明变量右偏、极端值或非线性关系明显。
论文里怎么写?
可以写:相关性分析显示,企业创新与数字普惠金融指数呈正相关关系,相关系数为 0.4395。该结果为后续回归提供了初步描述性证据,但尚不能解释为因果关系。控制变量之间未出现异常高相关,初步看不存在严重线性重合。
常见错误
最常见的错误是把“相关显著”写成“影响显著”。相关矩阵没有固定效应,没有控制变量,也没有处理内生性,所以它只能放在数据描述部分,不能当成研究假设的正式证据。
本页案例代码和输出
下面这部分是本教程对应的实际案例材料,方便你把前面的解释和真实输出对上。
Stata 代码
log using "/root/workspace/empirical-wizard/workspace/5b186599/analysis.log", replace text
global JOB_DIR "/root/workspace/empirical-wizard/workspace/5b186599"
set more off
adopath + "/root/ado/plus"
global DATA_PATH "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv"
import delimited "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv", clear case(preserve)
capture confirm global JOB_DIR
if _rc global JOB_DIR "."
quietly duplicates drop
local statvars "patent_count dfi_index roa lev size growth cashflow tobinq top1 dual"
local timevar "year"
local idvar "stkcd"
local dvvar "patent_count"
local ivvar "dfi_index"
tempfile ewiz_desc
tempname ewiz_post
postfile `ewiz_post' str64 variable double count mean sd min p25 p50 p75 max using `ewiz_desc', replace
foreach v of local statvars {
capture confirm numeric variable `v'
if !_rc {
quietly summarize `v', detail
post `ewiz_post' ("`v'") (r(N)) (r(mean)) (r(sd)) (r(min)) (r(p25)) (r(p50)) (r(p75)) (r(max))
}
}
postclose `ewiz_post'
preserve
use `ewiz_desc', clear
rename count N
export delimited using "$JOB_DIR/描述性统计.csv", replace
restore
quietly pwcorr `statvars', sig
matrix EWIZ_C = r(C)
matrix EWIZ_P = r(sig)
local nvars : word count `statvars'
preserve
clear
set obs `nvars'
gen str64 variable = ""
forvalues i = 1/`nvars' {
local vname : word `i' of `statvars'
replace variable = "`vname'" in `i'
}
forvalues j = 1/`nvars' {
gen c`j' = .
}
forvalues i = 1/`nvars' {
forvalues j = 1/`nvars' {
replace c`j' = EWIZ_C[`i', `j'] in `i'
}
}
forvalues j = 1/`nvars' {
local vname : word `j' of `statvars'
rename c`j' `vname'
}
export delimited using "$JOB_DIR/相关系数矩阵.csv", replace
restore
* 同时导出 p 值矩阵(上三角 p、下三角系数约定:这里直接把 p 矩阵单独导出
* 供 reporter 读取;渲染时组合成『下三角系数+星号 / 上三角 p』学术格式)
preserve
clear
set obs `nvars'
gen str64 variable = ""
forvalues i = 1/`nvars' {
local vname : word `i' of `statvars'
replace variable = "`vname'" in `i'
}
forvalues j = 1/`nvars' {
gen p`j' = .
}
forvalues i = 1/`nvars' {
forvalues j = 1/`nvars' {
capture replace p`j' = EWIZ_P[`i', `j'] in `i'
}
}
forvalues j = 1/`nvars' {
local vname : word `j' of `statvars'
rename p`j' `vname'
}
export delimited using "$JOB_DIR/相关系数矩阵_pvalue.csv", replace
restore
foreach v in `dvvar' `ivvar' {
if "`v'" != "" {
capture confirm numeric variable `v'
if !_rc {
quietly inspect `v'
local _nunique = r(N_unique)
quietly summarize `v', meanonly
local _vmin = r(min)
local _vmax = r(max)
// Treat as dummy ONLY when there are exactly 1-2 unique values AND they are 0/1.
if `_nunique' <= 2 & `_vmin' >= 0 & `_vmax' <= 1 & `_vmax' - `_vmin' <= 1 & `_vmax' == int(`_vmax') & `_vmin' == int(`_vmin') {
graph bar (mean) `v', title("`v' Distribution") ytitle("Share") blabel(bar, format(%9.3f))
}
else {
histogram `v', normal title("`v' Distribution") xtitle("`v'") ytitle("Frequency")
}
capture graph export "$JOB_DIR/distribution_`v'.png", replace width(1600)
}
}
}
if "`timevar'" != "" & "`dvvar'" != "" {
capture confirm variable `timevar'
if !_rc {
preserve
keep `timevar' patent_count dfi_index
collapse (mean) patent_count dfi_index, by(`timevar')
sort `timevar'
if "`ivvar'" != "" {
twoway (line `dvvar' `timevar', lcolor(navy) lwidth(medthick) msymbol(o)) (line `ivvar' `timevar', yaxis(2) lcolor(maroon) lpattern(dash) msymbol(diamond)), title("Core Variable Trends") xtitle("`timevar'") ytitle("`dvvar' mean", axis(1)) ytitle("`ivvar' mean", axis(2)) legend(order(1 "`dvvar'" 2 "`ivvar'"))
}
else {
twoway line `dvvar' `timevar', lcolor(navy) lwidth(medthick) msymbol(o) title("Outcome Trend") xtitle("`timevar'") ytitle("`dvvar' mean")
}
capture graph export "$JOB_DIR/descriptive_trend.png", replace width(1800)
restore
}
}
if "`idvar'" != "" & "`timevar'" != "" {
capture confirm variable `idvar'
capture confirm variable `timevar'
if !_rc {
preserve
collapse (count) obs_count=`timevar' (min) start_period=`timevar' (max) end_period=`timevar', by(`idvar')
export delimited using "$JOB_DIR/panel_structure.csv", replace
restore
}
}
di "描述性统计与相关分析输出完成"
log close输出表
| variable | patent_count | dfi_index | roa | lev | size | growth | cashflow | tobinq | top1 | dual |
|---|---|---|---|---|---|---|---|---|---|---|
| patent_count | 1 | .43950948 | .24073994 | .013024604 | .17620607 | -.027265593 | .033593308 | .019011619 | -.032499224 | .0060554333 |
| dfi_index | .43950948 | 1 | .010009783 | .0087096244 | .03340555 | -.021365453 | .012453728 | -.0013975492 | -.0043962095 | -.0011652668 |
| roa | .24073994 | .010009783 | 1 | .026359176 | -.039585255 | .044941634 | .02670249 | .015529391 | -.0061969026 | .025583275 |
| lev | .013024604 | .0087096244 | .026359176 | 1 | .070986755 | -.027704539 | .020903539 | .041491505 | .0043391068 | .00078530196 |
| size | .17620607 | .03340555 | -.039585255 | .070986755 | 1 | .0048936065 | -.062741034 | -.030523267 | -.033124272 | .010508359 |
| growth | -.027265593 | -.021365453 | .044941634 | -.027704539 | .0048936065 | 1 | -.012840015 | .042992894 | -.01781022 | .0097842375 |
| cashflow | .033593308 | .012453728 | .02670249 | .020903539 | -.062741034 | -.012840015 | 1 | -.016293354 | .013908384 | .056830361 |
| tobinq | .019011619 | -.0013975492 | .015529391 | .041491505 | -.030523267 | .042992894 | -.016293354 | 1 | -.0075492994 | -.0093645761 |
| top1 | -.032499224 | -.0043962095 | -.0061969026 | .0043391068 | -.033124272 | -.01781022 | .013908384 | -.0075492994 | 1 | .01563069 |
| dual | .0060554333 | -.0011652668 | .025583275 | .00078530196 | .010508359 | .0097842375 | .056830361 | -.0093645761 | .01563069 | 1 |
案例图
写作检查
本文在共用企业面板样本上报告相关分析,核心输出见 相关系数矩阵.csv。结果解释时同时关注样本口径、变量构造、系数方向、标准误和适用前提,避免只凭单个 p 值完成方法选择。
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。