Day 01 · 手写教程
描述性统计
第一张表不是凑数,是数据可信度体检
描述性统计是什么?
描述性统计就是论文里的第一张表。它不负责证明假设,也不负责告诉你因果关系;它只回答一个更早的问题:这份样本到底长什么样。读者看到 Table 1,应该能知道样本有多少、变量大概在什么范围、有没有明显右偏、有没有离谱的极端值。
本案例的有效样本是 720 个公司-年观测。企业创新 patent_count 的均值是 1.993,中位数是 2,最大值是 7;这说明它不是一个很平滑的连续变量,而是有计数特征。核心变量 dfi_index 在建模口径下已经标准化,均值约为 -0.063,标准差约为 1.014,所以后面回归里的系数要按标准化变量理解。
这张表怎么做?
先把论文主模型会用到的变量列出来:因变量、核心解释变量、控制变量都要在 Table 1 里出现。然后对每个变量输出 N、均值、标准差、最小值、中位数和最大值。不要只给均值和标准差;对专利计数这种变量,中位数和最大值比均值更能暴露分布形状。
实际操作时,先读入数据,生成 ln_patent1 = ln(1 + patent_count),再用 tabstat 或同类命令输出统计量。加 1 的原因很简单:有些企业当年没有专利,ln(0) 不存在。
结果应该怎么读?
- 先看
N。如果不同变量的 N 差很多,后面的回归样本会被缺失值吃掉。 - 再看均值和中位数。如果均值远大于中位数,变量通常右偏,需要考虑取对数或计数模型。
- 最后看最小值和最大值。它们能帮你发现缺失码、录入错误和没有处理过的极端值。
论文里怎么写?
可以这样写:表 1 报告了主要变量的描述性统计。样本为 2015-2020 年 A 股上市公司面板。企业创新的专利计数均值为 1.993,中位数为 2,说明样本企业的创新产出存在一定右偏;核心解释变量数字普惠金融指数在建模口径下已标准化,均值接近 0,标准差接近 1。
常见错误
不要把描述性统计写成“DFI 促进创新”。Table 1 只能说明样本分布,不能说明因果。也不要只贴表不解释;至少要说明样本量、核心变量量纲和因变量分布。
本页案例代码和输出
下面这部分是本教程对应的实际案例材料,方便你把前面的解释和真实输出对上。
Stata 代码
log using "/root/workspace/empirical-wizard/workspace/5b186599/analysis.log", replace text
global JOB_DIR "/root/workspace/empirical-wizard/workspace/5b186599"
set more off
adopath + "/root/ado/plus"
global DATA_PATH "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv"
import delimited "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv", clear case(preserve)
capture confirm global JOB_DIR
if _rc global JOB_DIR "."
quietly duplicates drop
local statvars "patent_count dfi_index roa lev size growth cashflow tobinq top1 dual"
local timevar "year"
local idvar "stkcd"
local dvvar "patent_count"
local ivvar "dfi_index"
tempfile ewiz_desc
tempname ewiz_post
postfile `ewiz_post' str64 variable double count mean sd min p25 p50 p75 max using `ewiz_desc', replace
foreach v of local statvars {
capture confirm numeric variable `v'
if !_rc {
quietly summarize `v', detail
post `ewiz_post' ("`v'") (r(N)) (r(mean)) (r(sd)) (r(min)) (r(p25)) (r(p50)) (r(p75)) (r(max))
}
}
postclose `ewiz_post'
preserve
use `ewiz_desc', clear
rename count N
export delimited using "$JOB_DIR/描述性统计.csv", replace
restore
quietly pwcorr `statvars', sig
matrix EWIZ_C = r(C)
matrix EWIZ_P = r(sig)
local nvars : word count `statvars'
preserve
clear
set obs `nvars'
gen str64 variable = ""
forvalues i = 1/`nvars' {
local vname : word `i' of `statvars'
replace variable = "`vname'" in `i'
}
forvalues j = 1/`nvars' {
gen c`j' = .
}
forvalues i = 1/`nvars' {
forvalues j = 1/`nvars' {
replace c`j' = EWIZ_C[`i', `j'] in `i'
}
}
forvalues j = 1/`nvars' {
local vname : word `j' of `statvars'
rename c`j' `vname'
}
export delimited using "$JOB_DIR/相关系数矩阵.csv", replace
restore
* 同时导出 p 值矩阵(上三角 p、下三角系数约定:这里直接把 p 矩阵单独导出
* 供 reporter 读取;渲染时组合成『下三角系数+星号 / 上三角 p』学术格式)
preserve
clear
set obs `nvars'
gen str64 variable = ""
forvalues i = 1/`nvars' {
local vname : word `i' of `statvars'
replace variable = "`vname'" in `i'
}
forvalues j = 1/`nvars' {
gen p`j' = .
}
forvalues i = 1/`nvars' {
forvalues j = 1/`nvars' {
capture replace p`j' = EWIZ_P[`i', `j'] in `i'
}
}
forvalues j = 1/`nvars' {
local vname : word `j' of `statvars'
rename p`j' `vname'
}
export delimited using "$JOB_DIR/相关系数矩阵_pvalue.csv", replace
restore
foreach v in `dvvar' `ivvar' {
if "`v'" != "" {
capture confirm numeric variable `v'
if !_rc {
quietly inspect `v'
local _nunique = r(N_unique)
quietly summarize `v', meanonly
local _vmin = r(min)
local _vmax = r(max)
// Treat as dummy ONLY when there are exactly 1-2 unique values AND they are 0/1.
if `_nunique' <= 2 & `_vmin' >= 0 & `_vmax' <= 1 & `_vmax' - `_vmin' <= 1 & `_vmax' == int(`_vmax') & `_vmin' == int(`_vmin') {
graph bar (mean) `v', title("`v' Distribution") ytitle("Share") blabel(bar, format(%9.3f))
}
else {
histogram `v', normal title("`v' Distribution") xtitle("`v'") ytitle("Frequency")
}
capture graph export "$JOB_DIR/distribution_`v'.png", replace width(1600)
}
}
}
if "`timevar'" != "" & "`dvvar'" != "" {
capture confirm variable `timevar'
if !_rc {
preserve
keep `timevar' patent_count dfi_index
collapse (mean) patent_count dfi_index, by(`timevar')
sort `timevar'
if "`ivvar'" != "" {
twoway (line `dvvar' `timevar', lcolor(navy) lwidth(medthick) msymbol(o)) (line `ivvar' `timevar', yaxis(2) lcolor(maroon) lpattern(dash) msymbol(diamond)), title("Core Variable Trends") xtitle("`timevar'") ytitle("`dvvar' mean", axis(1)) ytitle("`ivvar' mean", axis(2)) legend(order(1 "`dvvar'" 2 "`ivvar'"))
}
else {
twoway line `dvvar' `timevar', lcolor(navy) lwidth(medthick) msymbol(o) title("Outcome Trend") xtitle("`timevar'") ytitle("`dvvar' mean")
}
capture graph export "$JOB_DIR/descriptive_trend.png", replace width(1800)
restore
}
}
if "`idvar'" != "" & "`timevar'" != "" {
capture confirm variable `idvar'
capture confirm variable `timevar'
if !_rc {
preserve
collapse (count) obs_count=`timevar' (min) start_period=`timevar' (max) end_period=`timevar', by(`idvar')
export delimited using "$JOB_DIR/panel_structure.csv", replace
restore
}
}
di "描述性统计与相关分析输出完成"
log close输出表
| variable | N | mean | sd | min | p25 | p50 | p75 | max |
|---|---|---|---|---|---|---|---|---|
| patent_count | 720 | 1.9930556 | 1.3461764 | 0 | 1 | 2 | 3 | 7 |
| dfi_index | 720 | -.062502638 | 1.0140283 | -3.2634001 | -.72144997 | -.052749999 | .6358 | 3.2537999 |
| roa | 720 | .041655276 | 1.0799717 | -3.2021 | -.64324999 | .02565 | .78555 | 3.7595 |
| lev | 720 | .051649168 | 1.0138992 | -3.0769999 | -.65769994 | .1188 | .78215003 | 3.2701001 |
| size | 720 | -.06190528 | 1.0274159 | -3.0518999 | -.76375002 | -.045199998 | .65955001 | 2.7516999 |
| growth | 720 | -.023481252 | .9872914 | -2.4997001 | -.68540001 | -.054750003 | .62709999 | 3.191 |
| cashflow | 720 | .033964586 | 1.0026336 | -2.9795001 | -.59189999 | .017999999 | .73650002 | 3.7314 |
| tobinq | 720 | .060584169 | .99526453 | -3.1794 | -.59360003 | .1068 | .65715003 | 3.4525001 |
| top1 | 720 | -.02420889 | .98265254 | -2.8601999 | -.70795 | -.03805 | .64835 | 2.4839001 |
| dual | 720 | -.012043748 | 1.0300157 | -2.691 | -.77559996 | -.060199998 | .67095006 | 4.1808 |
补充输出
下面这些文件来自同一次案例运行或烟测输出,用来补齐主表之外的诊断信息。
panel_structure.csv
| stkcd | obs_count | start_period | end_period |
|---|---|---|---|
| F0000 | 6 | 2015 | 2020 |
| F0001 | 6 | 2015 | 2020 |
| F0002 | 6 | 2015 | 2020 |
| F0003 | 6 | 2015 | 2020 |
| F0004 | 6 | 2015 | 2020 |
| F0005 | 6 | 2015 | 2020 |
| F0006 | 6 | 2015 | 2020 |
| F0007 | 6 | 2015 | 2020 |
| F0008 | 6 | 2015 | 2020 |
| F0009 | 6 | 2015 | 2020 |
| F0010 | 6 | 2015 | 2020 |
| F0011 | 6 | 2015 | 2020 |
| F0012 | 6 | 2015 | 2020 |
| F0013 | 6 | 2015 | 2020 |
| F0014 | 6 | 2015 | 2020 |
| F0015 | 6 | 2015 | 2020 |
| F0016 | 6 | 2015 | 2020 |
| F0017 | 6 | 2015 | 2020 |
| F0018 | 6 | 2015 | 2020 |
| F0019 | 6 | 2015 | 2020 |
| F0020 | 6 | 2015 | 2020 |
| F0021 | 6 | 2015 | 2020 |
| F0022 | 6 | 2015 | 2020 |
| F0023 | 6 | 2015 | 2020 |
| F0024 | 6 | 2015 | 2020 |
| F0025 | 6 | 2015 | 2020 |
| F0026 | 6 | 2015 | 2020 |
| F0027 | 6 | 2015 | 2020 |
| F0028 | 6 | 2015 | 2020 |
| F0029 | 6 | 2015 | 2020 |
| F0030 | 6 | 2015 | 2020 |
| F0031 | 6 | 2015 | 2020 |
| F0032 | 6 | 2015 | 2020 |
| F0033 | 6 | 2015 | 2020 |
| F0034 | 6 | 2015 | 2020 |
| F0035 | 6 | 2015 | 2020 |
这里只展示前 36 行,完整文件保存在资产目录中。
相关系数矩阵.csv
| variable | patent_count | dfi_index | roa | lev | size | growth | cashflow | tobinq | top1 | dual |
|---|---|---|---|---|---|---|---|---|---|---|
| patent_count | 1 | .43950948 | .24073994 | .013024604 | .17620607 | -.027265593 | .033593308 | .019011619 | -.032499224 | .0060554333 |
| dfi_index | .43950948 | 1 | .010009783 | .0087096244 | .03340555 | -.021365453 | .012453728 | -.0013975492 | -.0043962095 | -.0011652668 |
| roa | .24073994 | .010009783 | 1 | .026359176 | -.039585255 | .044941634 | .02670249 | .015529391 | -.0061969026 | .025583275 |
| lev | .013024604 | .0087096244 | .026359176 | 1 | .070986755 | -.027704539 | .020903539 | .041491505 | .0043391068 | .00078530196 |
| size | .17620607 | .03340555 | -.039585255 | .070986755 | 1 | .0048936065 | -.062741034 | -.030523267 | -.033124272 | .010508359 |
| growth | -.027265593 | -.021365453 | .044941634 | -.027704539 | .0048936065 | 1 | -.012840015 | .042992894 | -.01781022 | .0097842375 |
| cashflow | .033593308 | .012453728 | .02670249 | .020903539 | -.062741034 | -.012840015 | 1 | -.016293354 | .013908384 | .056830361 |
| tobinq | .019011619 | -.0013975492 | .015529391 | .041491505 | -.030523267 | .042992894 | -.016293354 | 1 | -.0075492994 | -.0093645761 |
| top1 | -.032499224 | -.0043962095 | -.0061969026 | .0043391068 | -.033124272 | -.01781022 | .013908384 | -.0075492994 | 1 | .01563069 |
| dual | .0060554333 | -.0011652668 | .025583275 | .00078530196 | .010508359 | .0097842375 | .056830361 | -.0093645761 | .01563069 | 1 |
相关系数矩阵_pvalue.csv
| variable | patent_count | dfi_index | roa | lev | size | growth | cashflow | tobinq | top1 | dual |
|---|---|---|---|---|---|---|---|---|---|---|
| patent_count | 2.3083303e-35 | 5.9494361e-11 | .72716862 | 1.9633560e-06 | .4650985 | .36807188 | .61054552 | .38388494 | .87114561 | |
| dfi_index | 2.3083303e-35 | .78859872 | .81552684 | .37075645 | .56707507 | .73868072 | .97013813 | .90625918 | .97509962 | |
| roa | 5.9494361e-11 | .78859872 | .48007327 | .28880164 | .22842577 | .47437078 | .6774112 | .86816245 | .49309739 | |
| lev | .72716862 | .81552684 | .48007327 | .056927469 | .45794097 | .57548803 | .2661905 | .9074713 | .98321754 | |
| size | 1.9633560e-06 | .37075645 | .28880164 | .056927469 | .89571053 | .092520148 | .41347557 | .37480077 | .77833712 | |
| growth | .4650985 | .56707507 | .22842577 | .45794097 | .89571053 | .73088443 | .24925995 | .63328677 | .793253 | |
| cashflow | .36807188 | .73868072 | .47437078 | .57548803 | .092520148 | .73088443 | .66249871 | .70946801 | .12763354 | |
| tobinq | .61054552 | .97013813 | .6774112 | .2661905 | .41347557 | .24925995 | .66249871 | .83974481 | .80193251 | |
| top1 | .38388494 | .90625918 | .86816245 | .9074713 | .37480077 | .63328677 | .70946801 | .83974481 | .67542642 | |
| dual | .87114561 | .97509962 | .49309739 | .98321754 | .77833712 | .793253 | .12763354 | .80193251 | .67542642 |
案例图
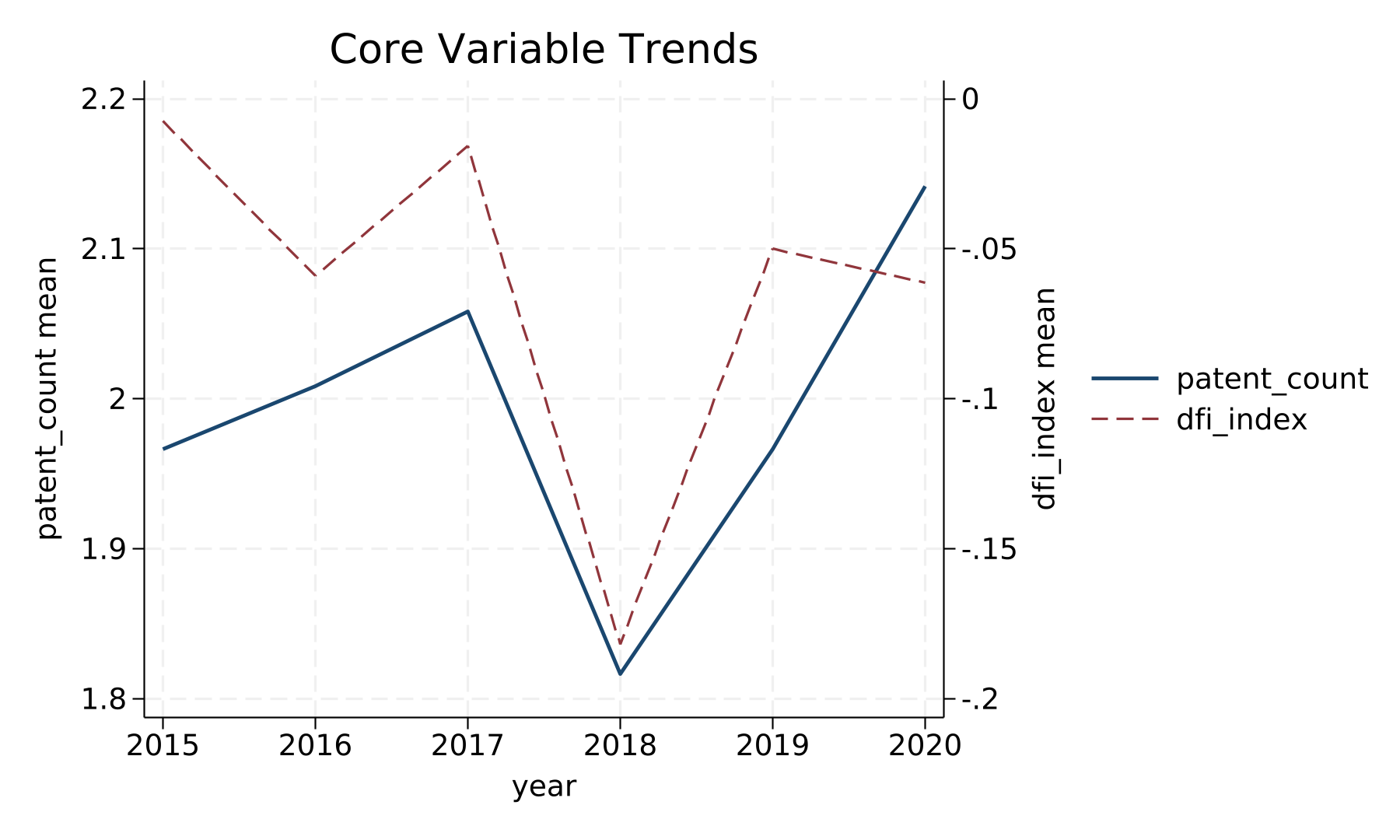
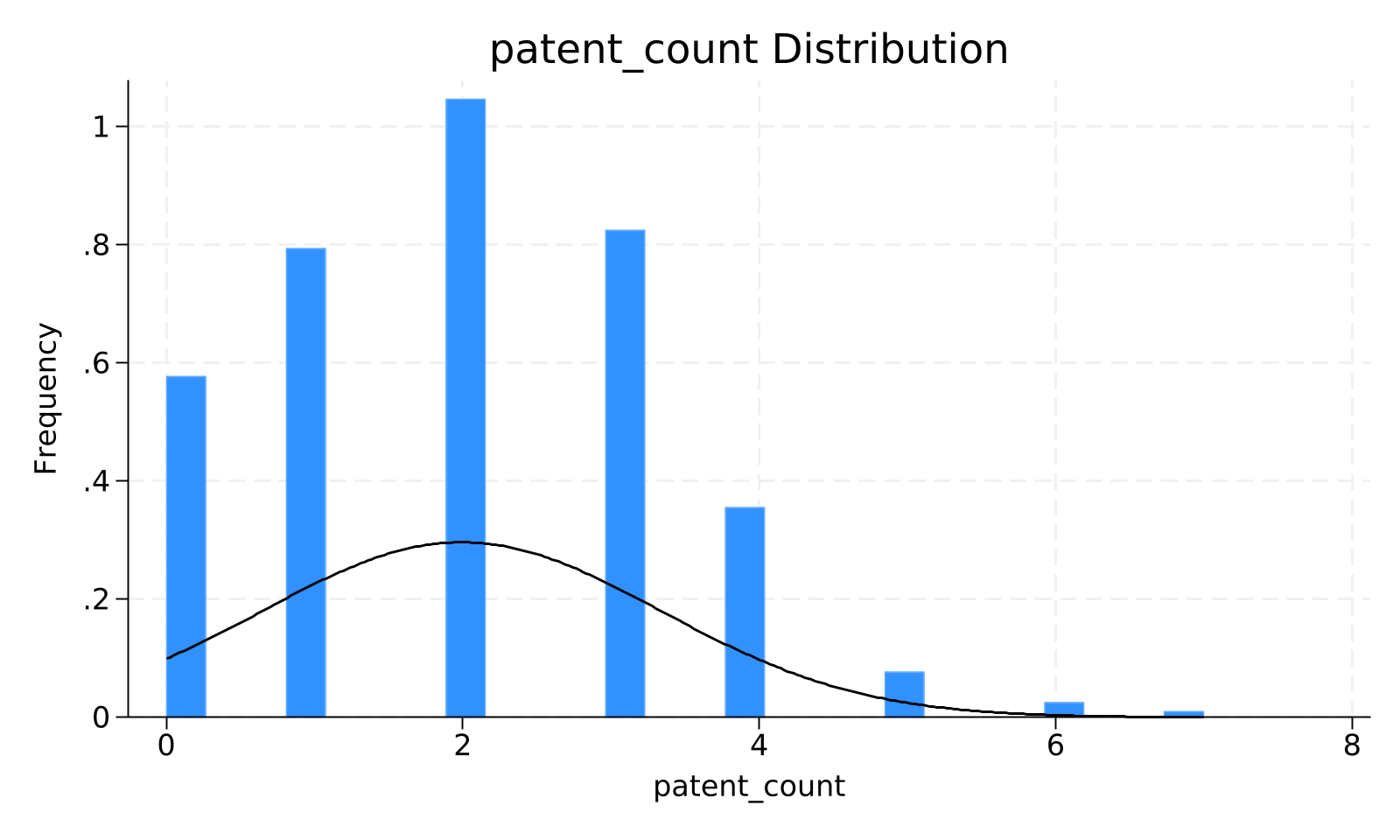
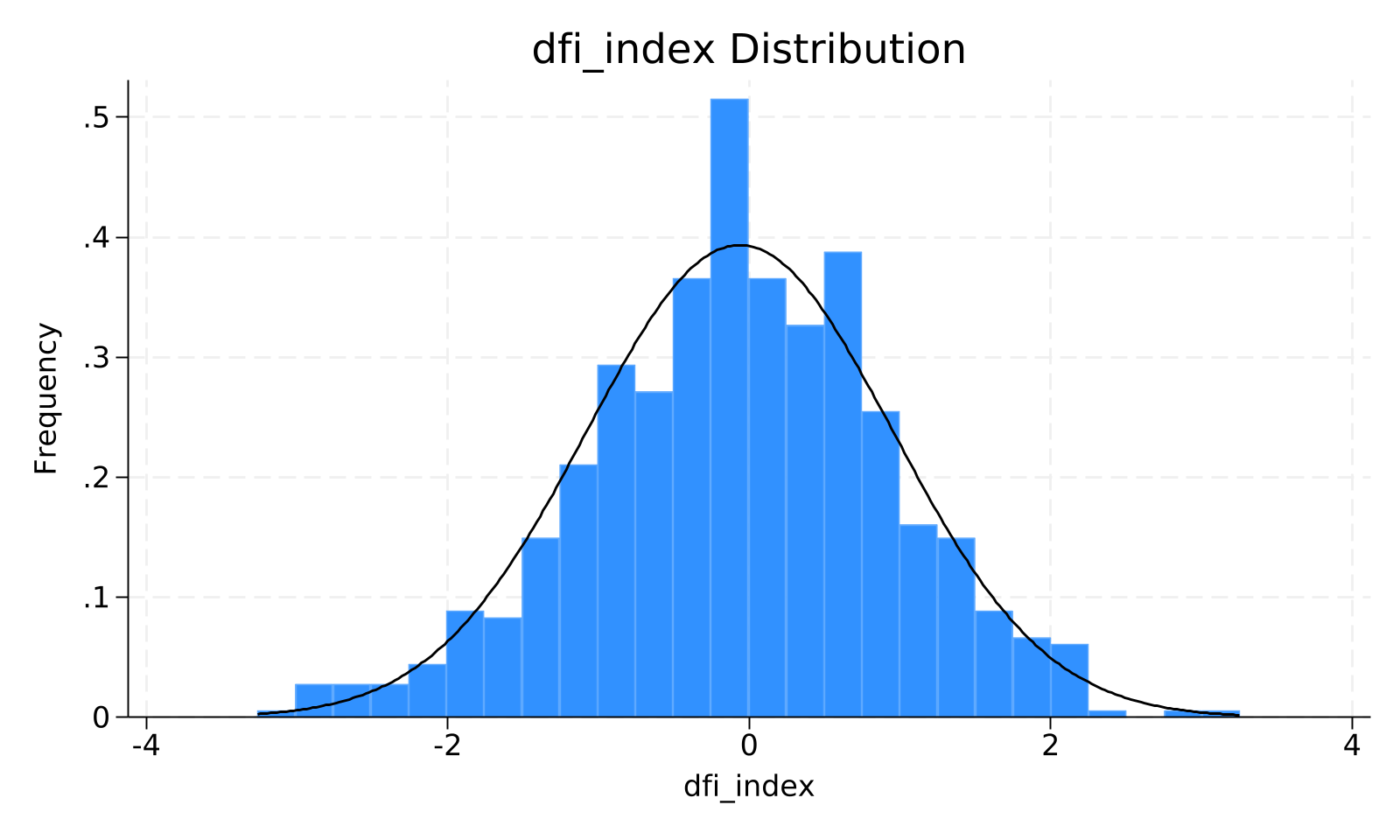
写作检查
本文在共用企业面板样本上报告描述性统计,核心输出见 描述性统计.csv。结果解释时同时关注样本口径、变量构造、系数方向、标准误和适用前提,避免只凭单个 p 值完成方法选择。
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。