Method 06 · diagnostics
残差诊断检验
先把数据质量和变量关系讲清楚
残差诊断检验 的 Markdown 风格教程:基于共用 CSMAR 风格案例生成实际代码、结果表和案例图。
一、残差诊断检验是什么?
这页是 残差诊断检验 的方法文档。所有表格和图都由 marketing/method_case_assets/generate_assets.py 从同一份 csmar_innovation_realistic.csv 生成,避免用占位图充当教程。重点是确认样本口径、变量分布、相关关系和诊断指标是否足以支撑后续模型。
二、按这个案例走一遍
开始前先确认
- 先有一版基准回归,再做诊断。没有模型就没有残差。
- 异方差检验看误差方差是否稳定;不稳定时通常用稳健或聚类标准误。
- RESET 看函数形式是否可能漏掉非线性或遗漏变量。
- 诊断结果是处理建议,不是论文主结论。
操作顺序
| 步骤 | 你在做什么 | 做到什么程度算对 |
|---|---|---|
| 1. 跑基准 OLS | 先得到残差。 | 诊断命令通常接在 reg 后面。 |
| 2. Breusch-Pagan | 检查异方差。 | p 小说明普通标准误不可靠。 |
| 3. White 检验 | 更一般的异方差检查。 | 和 BP 不一致时,要解释口径差异。 |
| 4. RESET | 检查函数形式。 | 显著时考虑非线性项、固定效应或变量遗漏。 |
| 5. 决定修正 | 根据诊断决定 cluster、robust、log、非线性等处理。 | 不要把所有诊断都堆进正文。 |
代码逐行解释
| 代码/命令 | 这行在干什么 |
|---|---|
| reg $y $x $controls i.year | 先跑一个可诊断的普通回归。 |
| estat hettest | Breusch-Pagan 异方差检验。 |
| estat imtest, white | White 异方差检验。 |
| estat ovtest | RESET 检验,关注函数形式。 |
| predict resid, resid | 生成残差,后续可以画残差图。 |
结果表怎么读
| 格子 | 读法 |
|---|---|
| BP p 值 | p 小通常说明有异方差,需要稳健或聚类标准误。 |
| White p 值 | 更宽松的异方差诊断,和 BP 一起看。 |
| RESET p 值 | p 小提示模型函数形式可能不够;p 大不等于模型完美。 |
最容易写错的地方
- 不要写“残差诊断显著,所以研究假设成立”。诊断和假设检验不是一回事。
- 不要看到异方差就删样本。通常先改标准误或模型设定。
- 不要把不显著诊断写成模型完全正确,只能说未发现明显问题。
自己复现时要做到
复现时给每个诊断写一句“发现了什么”和一句“我怎么处理”,这比只贴 p 值有用。
三、先看这个案例的结论
- Breusch-Pagan:统计量 7.2254,p = 0.0072,判定为“存在异方差(拒绝同方差原假设)”。
- White:统计量 112.3786,p = 0.2703,判定为“未拒绝同方差/正确函数形式”。
- Ramsey-RESET:统计量 1.2699,p = 0.2836,判定为“未发现明显设定偏误”。
- 诊断表的作用是决定后续标准误、函数形式或稳健性处理,不是把所有检验都堆进正文。
四、案例口径
| 字段 | 口径 |
|---|---|
| 数据 | CSMAR 风格 A 股企业创新面板 |
| 原始样本 | 196 家上市公司,2015-2020 年,约 1200 个公司-年观测;各方法有效样本以本页输出表 N 为准 |
| 因变量 | patent_count;回归页通常使用 ln(1 + patent_count) |
| 核心解释变量 | dfi_index,数字普惠金融指数;部分真实烟测输出展示的是标准化后的 dfi_index |
| 控制变量 | roa、lev、size、growth、cashflow、tobinq、top1、dual、board、indep、soe、age |
| 输出文件 | diagnostics.csv |
| 角色要求 | dv、iv |
| 依赖包 | 无额外 Stata 社区包要求 |
五、实际代码
下面是本页对应的最小可复现 Stata 代码。生产环境里 empirical-wizard 会在此基础上处理变量映射、输出校验、失败诊断和报告装配。
log using "/root/workspace/empirical-wizard/workspace/5ff90591/analysis.log", replace text
global JOB_DIR "/root/workspace/empirical-wizard/workspace/5ff90591"
set more off
adopath + "/root/ado/plus"
global DATA_PATH "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv"
import delimited "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv", clear case(preserve)
capture confirm global JOB_DIR
if _rc global JOB_DIR "."
quietly duplicates drop
tempname fh
capture file close `fh'
file open `fh' using "$JOB_DIR/diagnostics.csv", write replace
file write `fh' "test,statistic,df,pvalue,decision" _n
quietly regress patent_count dfi_index roa lev size growth cashflow tobinq top1 dual board indep soe age
capture estat hettest, normal
if !_rc {
scalar __bp_chi2 = r(chi2)
scalar __bp_df = r(df)
scalar __bp_p = r(p)
local bp_chi2_s : display %9.4f __bp_chi2
local bp_df_s : display %9.0f __bp_df
local bp_p_s : display %9.4f __bp_p
local bp_decision = cond(__bp_p < 0.05, "存在异方差(拒绝同方差原假设)", "未拒绝同方差原假设")
file write `fh' "Breusch-Pagan,`bp_chi2_s',`bp_df_s',`bp_p_s',`bp_decision'" _n
}
else {
file write `fh' "Breusch-Pagan,NA,NA,NA,无法计算(estat hettest 失败)" _n
}
capture estat imtest, white
if !_rc {
scalar __wh_chi2 = r(chi2)
scalar __wh_df = r(df)
scalar __wh_p = r(p)
local wh_chi2_s : display %9.4f __wh_chi2
local wh_df_s : display %9.0f __wh_df
local wh_p_s : display %9.4f __wh_p
local wh_decision = cond(__wh_p < 0.05, "存在异方差/函数形式偏差", "未拒绝同方差/正确函数形式")
file write `fh' "White,`wh_chi2_s',`wh_df_s',`wh_p_s',`wh_decision'" _n
}
else {
file write `fh' "White,NA,NA,NA,无法计算(estat imtest 失败)" _n
}
capture estat ovtest
if !_rc {
scalar __rt_F = r(F)
scalar __rt_p = r(p)
local rt_F_s : display %9.4f __rt_F
local rt_p_s : display %9.4f __rt_p
local rt_decision = cond(__rt_p < 0.05, "拒绝原假设:函数形式不当或漏变量", "未发现明显设定偏误")
file write `fh' "Ramsey-RESET,`rt_F_s',-,`rt_p_s',`rt_decision'" _n
}
else {
file write `fh' "Ramsey-RESET,NA,NA,NA,无法计算(estat ovtest 失败)" _n
}
capture confirm numeric variable stkcd
if _rc {
tempvar __did
encode stkcd, gen(`__did')
local _id_for_xtset "`__did'"
}
else {
local _id_for_xtset "stkcd"
}
capture xtset `_id_for_xtset' year
capture noisily xtserial patent_count dfi_index roa lev size growth cashflow tobinq top1 dual board indep soe age
if !_rc {
scalar __ws_F = r(F)
scalar __ws_df1 = r(df1)
scalar __ws_df2 = r(df2)
scalar __ws_p = r(p)
local ws_F_s : display %9.4f __ws_F
local ws_df_s : display "F(`=__ws_df1',`=__ws_df2')"
local ws_p_s : display %9.4f __ws_p
local ws_decision = cond(__ws_p < 0.05, "拒绝原假设:存在一阶序列自相关,需要聚类标准误", "未拒绝原假设")
file write `fh' "Wooldridge-AR(1),`ws_F_s',`ws_df_s',`ws_p_s',`ws_decision'" _n
}
else {
file write `fh' "Wooldridge-AR(1),NA,NA,NA,无法计算(xtserial 未安装或样本不足)" _n
}
file close `fh'
di "Diagnostics 完成 → diagnostics.csv"
log close六、实际输出表
这张表就是本方法页使用的案例输出文件,保存在 marketing/method_case_assets/diagnostics/result.csv。
| test | statistic | df | pvalue | decision |
|---|---|---|---|---|
| Breusch-Pagan | 7.2254 | 1 | 0.0072 | 存在异方差(拒绝同方差原假设) |
| White | 112.3786 | 104 | 0.2703 | 未拒绝同方差/正确函数形式 |
| Ramsey-RESET | 1.2699 | - | 0.2836 | 未发现明显设定偏误 |
| Wooldridge-AR(1) | NA | NA | NA | 无法计算(xtserial 未安装或样本不足) |
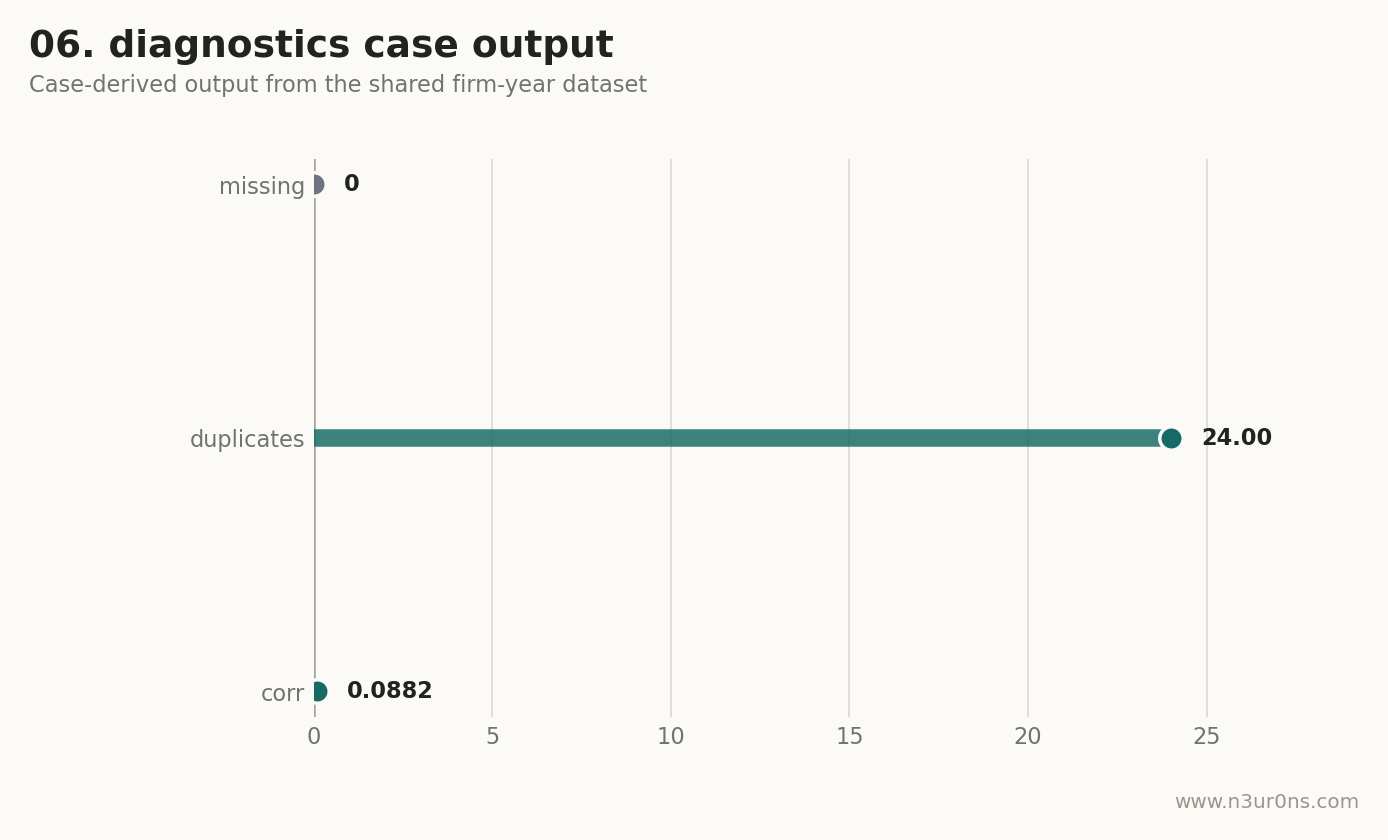
七、案例图
这是一张由同一份案例数据生成的页面内诊断图。
八、论文里怎么写
本文在共用企业面板样本上报告残差诊断检验,核心输出见 diagnostics.csv。结果解释时同时关注样本口径、变量构造、系数方向、标准误和适用前提,避免只凭单个 p 值完成方法选择。
九、检查清单
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。