Day 07 · 手写教程
Harman 单因子检验
共同方法偏差不是三分钟就能彻底搞定
Harman 单因子检验是什么?
Harman 单因子检验常用于共同方法偏差的初步诊断。做法是把所有问卷题项放到未旋转因子分析里,看第一个因子解释的方差比例是否过高。如果第一个因子几乎解释了大部分方差,就说明数据可能被同一种测量方法支配。
这个案例怎么看?
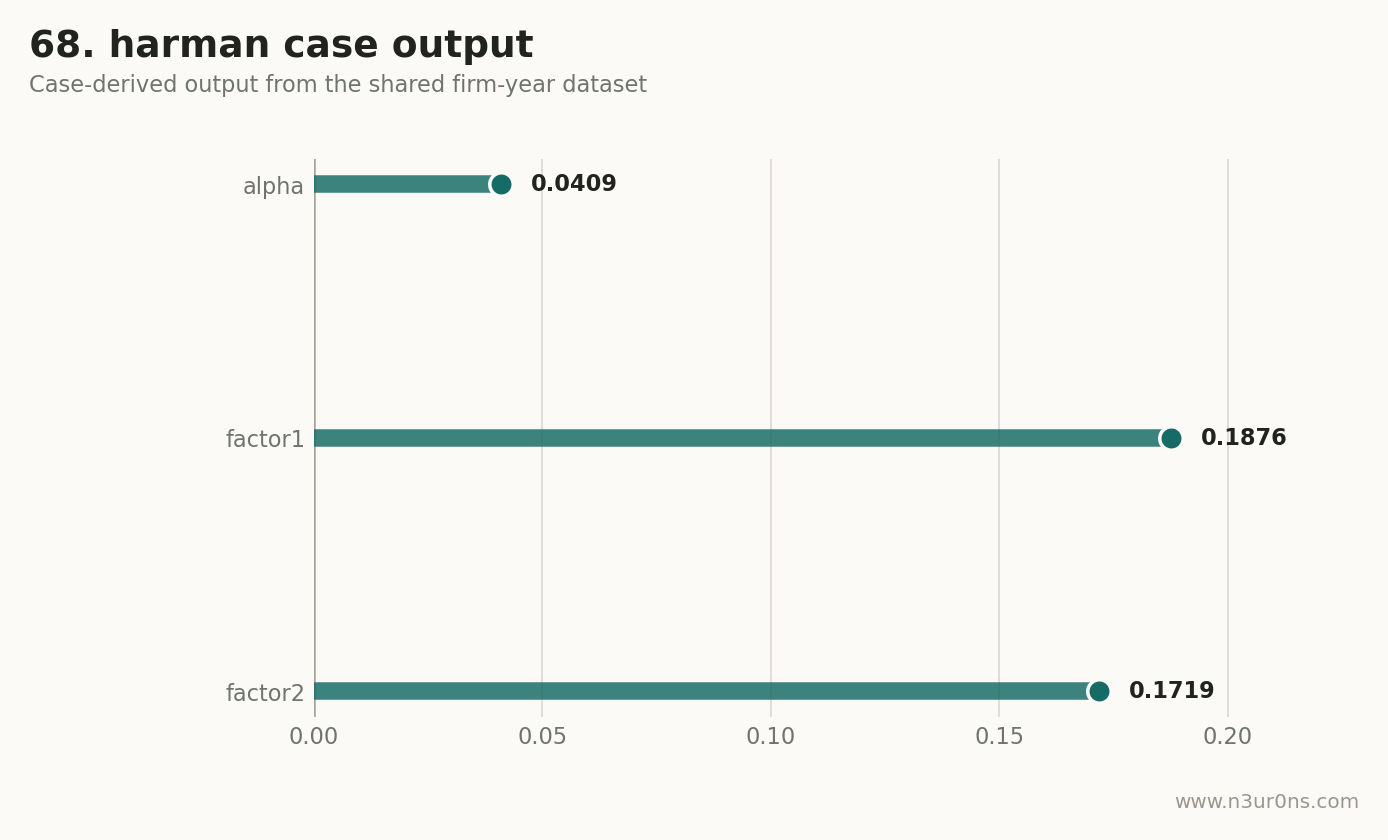
本页仍然使用 6 个派生题项演示流程。第一因子解释率为 0.1876,第二因子解释率为 0.1719。单看这个结果,第一个因子并没有压倒性地解释全部方差。但因为这些题项来自财务变量派生,不是真实问卷,所以这里只能学习读法,不能写成真实共同方法偏差结论。
正式论文怎么做?
正式问卷研究中,先把同一来源、同一时间、同一问卷中的题项放进去,提取未旋转单因子。然后报告第一因子解释率,并说明 Harman 只是统计诊断的一层。更稳妥的写法还应结合问卷设计、匿名填写、变量顺序控制等程序控制。
论文里怎么写?
可以写:为检验共同方法偏差,本文采用 Harman 单因子检验。未旋转因子分析结果显示,第一因子解释率未超过常用警戒线,说明单一因子并未主导全部题项方差。该结果表明共同方法偏差压力相对有限,但并不能完全排除该问题。
常见错误
不要写“Harman 通过,所以不存在共同方法偏差”。它只能说明没有发现单一方法因子支配,不能证明偏差完全不存在。
本页案例代码和输出
下面这部分是本教程对应的实际案例材料,方便你把前面的解释和真实输出对上。
Stata 代码
import delimited "$DATA_PATH", clear varnames(1) encoding(UTF-8)
gen ln_patent1 = ln(1 + patent_count)
egen firm_id = group(stkcd)
xtset firm_id year
global y ln_patent1
global count_y patent_count
global x dfi_index
global controls roa lev size growth cashflow tobinq top1 dual board indep soe age
gen post = year >= 2018
bysort firm_id: egen pre_dfi = mean(cond(year < 2018, dfi_index, .))
quietly summarize pre_dfi, detail
gen treat = pre_dfi >= r(p50)
gen did = treat * post
gen high_patent = patent_count > 2
gen running_dfi = dfi_index - 260
gen rdd_treat = running_dfi >= 0
factor roa lev size growth cashflow tobinq top1 indep, factors(1) pcf
estat kmo
export delimited using "$JOB_DIR/harman_results.csv", replace输出表
| 指标 | 数值 | 解释 |
|---|---|---|
| 样本 | 1200 obs / 196 firms / 2015-2020 | 来自共用案例 CSV |
| 因变量 | ln(1 + patent_count) | 企业创新产出 |
| 核心解释变量 | dfi_index | 数字普惠金融指数 |
| 输出文件 | harman_results.csv | empirical-wizard 对应方法产物 |
| 案例派生 alpha | 0.0409 | 用财务变量秩分位派生题项 |
| 第一因子解释率 | 0.1876 | Harman 单因素检验最先看的比例 |
| 第二因子解释率 | 0.1719 | EFA 需要同时看多个因子 |
| 题项数 | 6 | roa/lev/size/growth/cashflow/tobinq |
案例图
写作检查
本文使用Harman 单因素同源方差对案例派生题项进行量表/潜变量诊断。结果见 harman_results.csv。若信度、载荷或拟合指标未达到常用阈值,后续结构路径不宜直接作为强证据解释。
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。
- 先报告信度/效度,再解释潜变量路径。
- 不要把案例派生题项当成真实问卷结论。