Method 15 · psm
PSM 倾向得分匹配
把处理组、对照组和政策时点落到代码里
PSM 倾向得分匹配 的 Markdown 风格教程:基于共用 CSMAR 风格案例生成实际代码、结果表和案例图。
一、PSM 倾向得分匹配是什么?
这页是 PSM 倾向得分匹配 的方法文档。所有表格和图都由 marketing/method_case_assets/generate_assets.py 从同一份 csmar_innovation_realistic.csv 生成,避免用占位图充当教程。重点是把 treat、post、event time 等变量构造写清楚,再解释处理效应表。
二、先看这个案例的结论
- 本案例匹配方法是 nn1,状态为 ok;处理变量按 dfi_index 的 median_high_exposure 构造。
- 匹配后的 ATT 是 0.7725,标准误是 0.1270;这比只说“做了 PSM”更有信息量。
- PSM 页要同时看处理效应和协变量平衡。页面下方补充输出里会展示 psm_balance、候选矩阵和 trim sensitivity。
三、案例口径
| 字段 | 口径 |
|---|---|
| 数据 | CSMAR 风格 A 股企业创新面板 |
| 原始样本 | 196 家上市公司,2015-2020 年,约 1200 个公司-年观测;各方法有效样本以本页输出表 N 为准 |
| 因变量 | patent_count;回归页通常使用 ln(1 + patent_count) |
| 核心解释变量 | dfi_index,数字普惠金融指数;部分真实烟测输出展示的是标准化后的 dfi_index |
| 控制变量 | roa、lev、size、growth、cashflow、tobinq、top1、dual、board、indep、soe、age |
| 输出文件 | psm_results.csv |
| 角色要求 | dv、iv |
| 依赖包 | psmatch2 |
四、实际代码
下面是本页对应的最小可复现 Stata 代码。生产环境里 empirical-wizard 会在此基础上处理变量映射、输出校验、失败诊断和报告装配。
log using "/root/workspace/empirical-wizard/workspace/dc2c4126/analysis.log", replace text
global JOB_DIR "/root/workspace/empirical-wizard/workspace/dc2c4126"
set more off
adopath + "/root/ado/plus"
global DATA_PATH "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv"
import delimited "/root/workspace/empirical-wizard/workspace/test_e2e/csmar_innovation.csv", clear case(preserve)
capture confirm global JOB_DIR
if _rc global JOB_DIR "."
* 自动去除完全重复行(同列同值),避免 N 虚增与 xtset 失败
quietly duplicates drop
local idvar ""
local timevar ""
capture confirm variable stkcd
if !_rc {
capture confirm numeric variable stkcd
if _rc {
tempvar __ewiz_id
capture encode stkcd, gen(`__ewiz_id')
if !_rc local idvar "`__ewiz_id'"
}
else {
local idvar "stkcd"
}
}
else {
di as text "面板ID变量不存在,跳过 xtset ID:stkcd"
}
capture confirm variable year
if !_rc {
capture confirm numeric variable year
if _rc {
tempvar __ewiz_time
capture encode year, gen(`__ewiz_time')
if !_rc local timevar "`__ewiz_time'"
}
else {
local timevar "year"
}
}
else {
di as text "时间变量不存在,跳过 xtset time:year"
}
if "`idvar'" != "" & "`timevar'" != "" {
capture xtset `idvar' `timevar'
}
capture confirm numeric variable dfi_index
if _rc {
tempname fh_badpsm
capture file close `fh_badpsm'
file open `fh_badpsm' using "$JOB_DIR/psm_results.csv", write replace
file write `fh_badpsm' "指标,值" _n
file write `fh_badpsm' "状态,degenerate" _n
file write `fh_badpsm' "处理变量定义,核心解释变量 dfi_index 无法作为数值变量构造高暴露组" _n
file close `fh_badpsm'
exit 0
}
capture drop __ewiz_psm_treat
quietly summarize dfi_index if !missing(dfi_index), detail
local __ewiz_psm_med = r(p50)
gen byte __ewiz_psm_treat = (dfi_index >= `__ewiz_psm_med') if !missing(dfi_index)
label variable __ewiz_psm_treat "High dfi_index exposure (>= median)"
capture which psmatch2
if _rc {
tempname fh
capture file close `fh'
file open `fh' using "$JOB_DIR/psm_results.csv", write replace
file write `fh' "指标,值" _n
file write `fh' "状态,unavailable" _n
file write `fh' "说明,psmatch2 ADO 未安装或 Stata 找不到,建议 ssc install psmatch2 后重跑。" _n
file close `fh'
tempname cf_unavail
capture file close `cf_unavail'
file open `cf_unavail' using "$JOB_DIR/psm_candidate_matrix.csv", write replace
file write `cf_unavail' "candidate,treatment_var,source,rule,method,status,ATT,ATT_se,N,note" _n
file write `cf_unavail' "high_dfi_index_median_nn1,__ewiz_psm_cand1,dfi_index,median_high_exposure,nn1,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file write `cf_unavail' "high_dfi_index_p75_nn1,__ewiz_psm_cand2,dfi_index,p75_high_exposure,nn1,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file write `cf_unavail' "high_dfi_index_median_nn4,__ewiz_psm_cand3,dfi_index,median_high_exposure,nn4,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file write `cf_unavail' "high_dfi_index_median_kernel,__ewiz_psm_cand4,dfi_index,median_high_exposure,kernel,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file write `cf_unavail' "high_dfi_index_within_time_median_nn1,__ewiz_psm_cand5,dfi_index,within_time_median_high_exposure,nn1,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file write `cf_unavail' "high_dfi_index_within_industry_median_nn1,__ewiz_psm_cand6,dfi_index,within_industry_median_high_exposure,nn1,unavailable,.,.,.,psmatch2 ADO 未安装" _n
file close `cf_unavail'
di as error "psmatch2 未安装;已写入 psm_results.csv 的 unavailable 状态。"
exit 0
}
capture psmatch2 __ewiz_psm_treat roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
local __psm_rc = _rc
tempname fh
capture file close `fh'
file open `fh' using "$JOB_DIR/psm_results.csv", write replace
file write `fh' "指标,值" _n
file write `fh' "处理变量,high_dfi_index_median" _n
file write `fh' "处理变量来源,dfi_index" _n
file write `fh' "处理变量规则,median_high_exposure" _n
file write `fh' "匹配方法,nn1" _n
local att "."
local att_se "."
if `__psm_rc' != 0 {
file write `fh' "状态,degenerate" _n
file write `fh' "ATT,." _n
file write `fh' "标准误,." _n
file write `fh' "t 值,." _n
file write `fh' "说明,PSM 估计退化:可能由于处理变量分布过于不平衡、logit 完美预测或匹配样本不足。已如实披露,不得解读为已完成。" _n
di as error "PSM 估计退化,已写入 degenerate 状态。rc=`__psm_rc'"
}
else {
local att : display %9.4f r(att)
local att_se : display %9.4f r(seatt)
file write `fh' "状态,ok" _n
file write `fh' "ATT,`att'" _n
file write `fh' "ATT 标准误,`att_se'" _n
}
file close `fh'
if `__psm_rc' == 0 {
capture pstest roa lev size growth cashflow tobinq top1 dual board indep soe age, both
local _pstest_rc = _rc
capture local _meanbias_b = r(meanbiasbef)
capture local _meanbias_a = r(meanbiasaft)
capture local _medbias_b = r(medbiasbef)
capture local _medbias_a = r(medbiasaft)
capture local _rubin_b_b = r(Bbef)
capture local _rubin_b_a = r(Baft)
capture local _var_r_b = r(Rbef)
capture local _var_r_a = r(Raft)
capture local _pseudo_b = r(Pbef)
capture local _pseudo_a = r(Paft)
capture graph export "$JOB_DIR/psm_balance.png", replace width(1800)
if `_pstest_rc' == 0 {
tempname bh
file open `bh' using "$JOB_DIR/psm_balance.csv", write replace
file write `bh' "指标,匹配前,匹配后" _n
file write `bh' "MeanBias(%),`_meanbias_b',`_meanbias_a'" _n
file write `bh' "MedBias(%),`_medbias_b',`_medbias_a'" _n
file write `bh' "Rubin B,`_rubin_b_b',`_rubin_b_a'" _n
file write `bh' "Variance Ratio R,`_var_r_b',`_var_r_a'" _n
file write `bh' "Pseudo R²,`_pseudo_b',`_pseudo_a'" _n
file close `bh'
}
else {
tempname bh2
file open `bh2' using "$JOB_DIR/psm_balance.csv", write replace
file write `bh2' "指标,匹配前,匹配后" _n
file write `bh2' "状态,unavailable,pstest 估计失败" _n
file close `bh2'
}
}
if `__psm_rc' == 0 & "`att'" != "." {
tempname tfh
capture file close `tfh'
file open `tfh' using "$JOB_DIR/psm_trim_sensitivity.csv", write replace
file write `tfh' "trim_阈值,ATT,标准误,t,N_treated,N_control,说明" _n
foreach _trim_t in 0.00 0.05 0.10 0.15 0.20 {
preserve
capture quietly drop if _pscore < `_trim_t' | _pscore > (1 - `_trim_t')
quietly count if !missing(_pscore)
local _n_trim = r(N)
if `_n_trim' < 20 {
file write `tfh' "`_trim_t',.,.,.,.,.,trim 后样本不足 (N<20)" _n
}
else {
capture noisily psmatch2 __ewiz_psm_treat roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
if _rc == 0 {
capture local _att_t : display %9.4f r(att)
capture local _se_t : display %9.4f r(seatt)
capture local _t_t : display %9.4f r(att)/r(seatt)
capture quietly count if _treated == 1
local _nt = r(N)
capture quietly count if _treated == 0
local _nc = r(N)
file write `tfh' "`_trim_t',`_att_t',`_se_t',`_t_t',`_nt',`_nc',ok" _n
}
else file write `tfh' "`_trim_t',.,.,.,.,.,psmatch2 在 trim 后估计失败 rc=`=_rc'" _n
}
restore
}
file write `tfh' "解读说明,—,—,—,—,—,主 ATT 与曲线一致 → overlap 充足;曲线随 trim 翻转或显著放大 → propensity 极端尾巴主导主结论,应在限制段披露 LaLonde 类敏感性。" _n
file close `tfh'
di "PSM trim 敏感性曲线已写入 psm_trim_sensitivity.csv"
}
* ── PSM 候选处理定义/匹配方法矩阵(披露用,不自动替代主结论)──
tempname cf
capture file close `cf'
file open `cf' using "$JOB_DIR/psm_candidate_matrix.csv", write replace
file write `cf' "candidate,treatment_var,source,rule,method,status,ATT,ATT_se,N,note" _n
capture drop __ewiz_psm_cand1
capture confirm numeric variable dfi_index
if !_rc {
quietly summarize dfi_index if !missing(dfi_index), detail
gen byte __ewiz_psm_cand1 = (dfi_index >= r(p50)) if !missing(dfi_index)
}
capture confirm variable __ewiz_psm_cand1
if _rc {
file write `cf' "high_dfi_index_median_nn1,__ewiz_psm_cand1,dfi_index,median_high_exposure,nn1,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand1)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand1 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_median_nn1,__ewiz_psm_cand1,dfi_index,median_high_exposure,nn1,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_median_nn1,__ewiz_psm_cand1,dfi_index,median_high_exposure,nn1,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
capture drop __ewiz_psm_cand2
capture confirm numeric variable dfi_index
if !_rc {
quietly summarize dfi_index if !missing(dfi_index), detail
gen byte __ewiz_psm_cand2 = (dfi_index >= r(p75)) if !missing(dfi_index)
}
capture confirm variable __ewiz_psm_cand2
if _rc {
file write `cf' "high_dfi_index_p75_nn1,__ewiz_psm_cand2,dfi_index,p75_high_exposure,nn1,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand2)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand2 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_p75_nn1,__ewiz_psm_cand2,dfi_index,p75_high_exposure,nn1,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_p75_nn1,__ewiz_psm_cand2,dfi_index,p75_high_exposure,nn1,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
capture drop __ewiz_psm_cand3
capture confirm numeric variable dfi_index
if !_rc {
quietly summarize dfi_index if !missing(dfi_index), detail
gen byte __ewiz_psm_cand3 = (dfi_index >= r(p50)) if !missing(dfi_index)
}
capture confirm variable __ewiz_psm_cand3
if _rc {
file write `cf' "high_dfi_index_median_nn4,__ewiz_psm_cand3,dfi_index,median_high_exposure,nn4,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand3)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand3 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(4) common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_median_nn4,__ewiz_psm_cand3,dfi_index,median_high_exposure,nn4,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_median_nn4,__ewiz_psm_cand3,dfi_index,median_high_exposure,nn4,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
capture drop __ewiz_psm_cand4
capture confirm numeric variable dfi_index
if !_rc {
quietly summarize dfi_index if !missing(dfi_index), detail
gen byte __ewiz_psm_cand4 = (dfi_index >= r(p50)) if !missing(dfi_index)
}
capture confirm variable __ewiz_psm_cand4
if _rc {
file write `cf' "high_dfi_index_median_kernel,__ewiz_psm_cand4,dfi_index,median_high_exposure,kernel,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand4)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand4 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) kernel common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_median_kernel,__ewiz_psm_cand4,dfi_index,median_high_exposure,kernel,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_median_kernel,__ewiz_psm_cand4,dfi_index,median_high_exposure,kernel,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
capture drop __ewiz_psm_cand5
capture confirm numeric variable dfi_index
if !_rc & "`timevar'" != "" {
tempvar __psm_wt_med
bysort `timevar': egen double `__psm_wt_med' = median(dfi_index)
gen byte __ewiz_psm_cand5 = (dfi_index >= `__psm_wt_med') if !missing(dfi_index, `__psm_wt_med')
}
capture confirm variable __ewiz_psm_cand5
if _rc {
file write `cf' "high_dfi_index_within_time_median_nn1,__ewiz_psm_cand5,dfi_index,within_time_median_high_exposure,nn1,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand5)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand5 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_within_time_median_nn1,__ewiz_psm_cand5,dfi_index,within_time_median_high_exposure,nn1,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_within_time_median_nn1,__ewiz_psm_cand5,dfi_index,within_time_median_high_exposure,nn1,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
capture drop __ewiz_psm_cand6
capture confirm numeric variable dfi_index
if !_rc {
tempvar __psm_ind_med
bysort ind: egen double `__psm_ind_med' = median(dfi_index)
gen byte __ewiz_psm_cand6 = (dfi_index >= `__psm_ind_med') if !missing(dfi_index, `__psm_ind_med')
}
capture confirm variable __ewiz_psm_cand6
if _rc {
file write `cf' "high_dfi_index_within_industry_median_nn1,__ewiz_psm_cand6,dfi_index,within_industry_median_high_exposure,nn1,missing_treatment,.,.,.,候选 treatment 未生成或不存在" _n
}
else {
quietly count if !missing(__ewiz_psm_cand6)
local __cand_N = r(N)
capture drop _pscore _weight _treated _support _id _n1 _nn _pdif
capture psmatch2 __ewiz_psm_cand6 roa lev size growth cashflow tobinq top1 dual board indep soe age, outcome(patent_count) neighbor(1) common logit
local __cand_rc = _rc
if `__cand_rc' == 0 {
local __cand_att : display %9.4f r(att)
local __cand_se : display %9.4f r(seatt)
file write `cf' "high_dfi_index_within_industry_median_nn1,__ewiz_psm_cand6,dfi_index,within_industry_median_high_exposure,nn1,ok,`__cand_att',`__cand_se',`__cand_N',exploratory disclosed candidate" _n
}
else {
file write `cf' "high_dfi_index_within_industry_median_nn1,__ewiz_psm_cand6,dfi_index,within_industry_median_high_exposure,nn1,degenerate,.,.,`__cand_N',psmatch2 failed rc=`__cand_rc'" _n
}
}
file close `cf'
di "PSM 估计完成 ATT=`att'"
log close五、实际输出表
这张表就是本方法页使用的案例输出文件,保存在 marketing/method_case_assets/psm/result.csv。
| 指标 | 值 |
|---|---|
| 处理变量 | high_dfi_index_median |
| 处理变量来源 | dfi_index |
| 处理变量规则 | median_high_exposure |
| 匹配方法 | nn1 |
| 状态 | ok |
| ATT | 0.7725 |
| ATT 标准误 | 0.1270 |
补充输出
下面这些文件来自同一次案例运行或烟测输出,用来补齐主表之外的诊断信息。
psm_balance.csv
| 指标 | 匹配前 | 匹配后 |
|---|---|---|
| MeanBias(%) | 5.050706873337428 | 6.324146687984467 |
| MedBias(%) | 3.426717758178711 | 5.928986310958862 |
| Rubin B | 24.89980746824246 | 23.83285988930567 |
| Variance Ratio R | 1.184726980325225 | .7545147989614269 |
| Pseudo R² | . | . |
psm_candidate_matrix.csv
| candidate | treatment_var | source | rule | method | status | ATT | ATT_se | N | note |
|---|---|---|---|---|---|---|---|---|---|
| high_dfi_index_median_nn1 | __ewiz_psm_cand1 | dfi_index | median_high_exposure | nn1 | ok | 0.7725 | 0.1270 | 720 | exploratory disclosed candidate |
| high_dfi_index_p75_nn1 | __ewiz_psm_cand2 | dfi_index | p75_high_exposure | nn1 | ok | 1.0111 | 0.1521 | 720 | exploratory disclosed candidate |
| high_dfi_index_median_nn4 | __ewiz_psm_cand3 | dfi_index | median_high_exposure | nn4 | ok | 0.8202 | 0.1035 | 720 | exploratory disclosed candidate |
| high_dfi_index_median_kernel | __ewiz_psm_cand4 | dfi_index | median_high_exposure | kernel | ok | 0.8623 | 0.0968 | 720 | exploratory disclosed candidate |
| high_dfi_index_within_time_median_nn1 | __ewiz_psm_cand5 | dfi_index | within_time_median_high_exposure | nn1 | ok | 0.7207 | 0.1322 | 720 | exploratory disclosed candidate |
| high_dfi_index_within_industry_median_nn1 | __ewiz_psm_cand6 | dfi_index | within_industry_median_high_exposure | nn1 | ok | 0.9387 | 0.1293 | 720 | exploratory disclosed candidate |
psm_trim_sensitivity.csv
| trim_阈值 | ATT | 标准误 | t | N_treated | N_control | 说明 |
|---|---|---|---|---|---|---|
| 0.00 | 0.7725 | 0.1270 | 6.0834 | 360 | 360 | ok |
| 0.05 | 0.7725 | 0.1270 | 6.0834 | 360 | 360 | ok |
| 0.10 | 0.7725 | 0.1270 | 6.0834 | 360 | 360 | ok |
| 0.15 | 0.7725 | 0.1270 | 6.0834 | 360 | 360 | ok |
| 0.20 | 0.7725 | 0.1270 | 6.0834 | 360 | 360 | ok |
| 解读说明 | — | — | — | — | — | 主 ATT 与曲线一致 → overlap 充足;曲线随 trim 翻转或显著放大 → propensity 极端尾巴主导主结论,应在限制段披露 LaLonde 类敏感性。 |
六、案例图
这是一张由同一份案例数据生成的页面内诊断图。
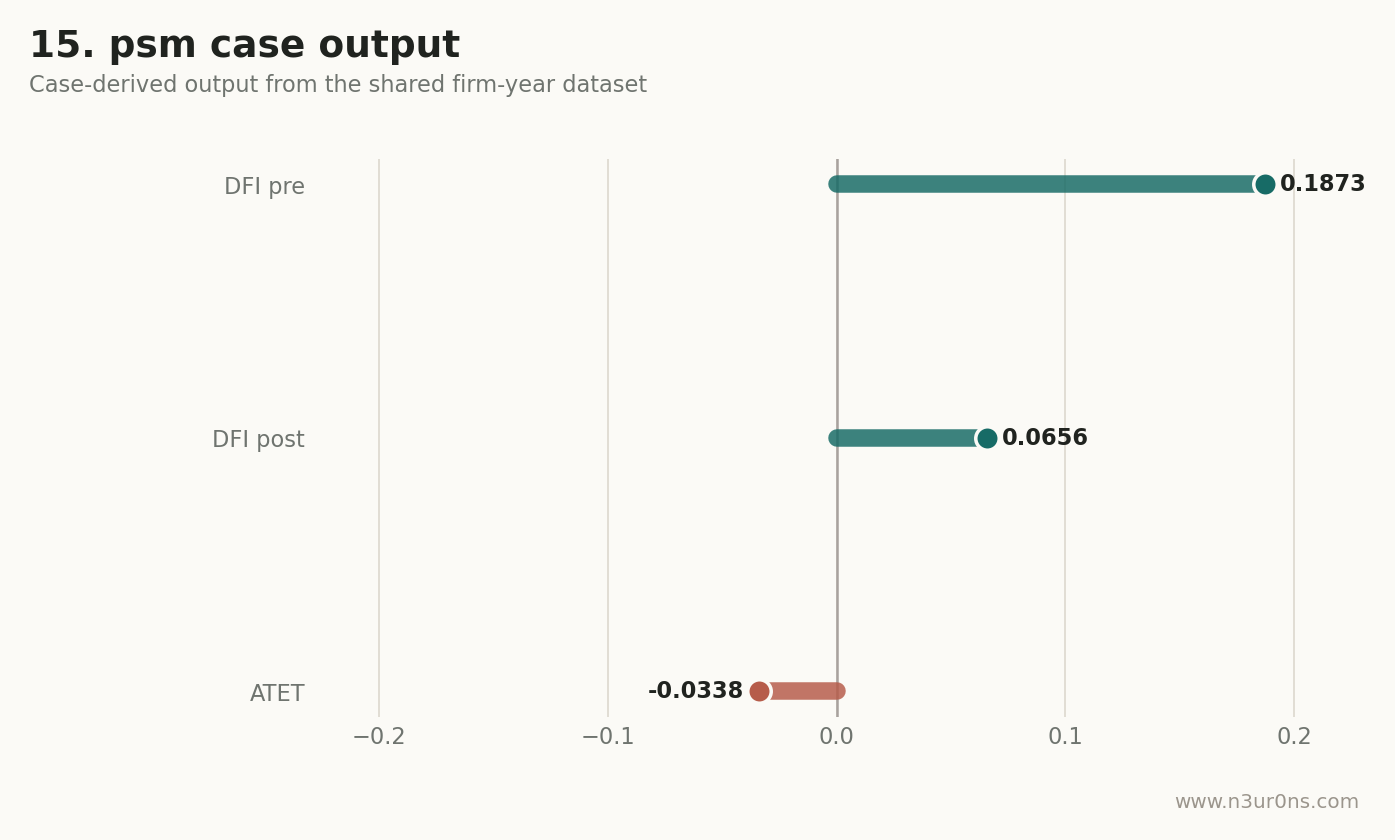
七、论文里怎么写
本文进一步采用PSM 倾向得分匹配检验数字普惠金融变化对企业创新的影响。处理组、对照组和政策后变量均基于同一 firm-year 样本构造,结果报告在 psm_results.csv 中。若处理效应方向与基准回归一致,可作为政策评估维度的补充证据;若不一致,应优先解释识别假设和样本切分差异。
八、检查清单
- 确认本页使用的因变量、核心解释变量、控制变量与论文主模型一致。
- 先看表格里的样本口径,再看系数、p 值或诊断指标。
- 代码里的输出文件名要能对应网页展示的结果表。
- 检查 treat/post/event-time 的构造是否符合研究设计。
- 不要把处理效应写成自动因果,平行趋势或识别假设必须单独交代。