e2e 集成测试
本报告仅整理实证分析结果、变量定义、模型估计、稳健性与诊断输出;引言、文献综述、理论分析、结论与政策启示等完整论文写作内容需由研究者基于本报告自行完成。
| 变量名称 | 符号 | 定义 | 测量方式 |
|---|---|---|---|
| 结果变量 | Y | 结果变量,用于衡量研究对象的最终表现水平。 | 由数据列dv直接度量,数值越大表示结果表现越高。 |
| 处理变量 | T | 处理变量,用于衡量研究对象接受处理或具备相关因素的程度。 | 由数据列iv直接度量,数值越大表示处理强度越高。 |
| 控制变量一 | C1 | 控制变量一,用于控制影响结果变量的其他可观测因素。 | 由数据列ctrl1直接度量。 |
| 控制变量二 | C2 | 控制变量二,用于控制影响结果变量的其他可观测因素。 | 由数据列ctrl2直接度量。 |
注:对数变量均采用自然对数 ln;虚拟变量取值为 0/1。
| 变量 | N | 均值 | 标准差 | 最小值 | 中位数 | 最大值 |
|---|---|---|---|---|---|---|
| dv | 960 | 0.277 | 0.832 | -2.296 | 0.269 | 2.874 |
| iv | 960 | -0.011 | 0.955 | -3.482 | 0.031 | 3.014 |
| m | 960 | -0.002 | 0.646 | -2.001 | 0.013 | 1.926 |
| ctrl1 | 960 | -0.013 | 1.022 | -3.004 | -0.019 | 3.081 |
| ctrl2 | 960 | 0.080 | 1.000 | -2.945 | 0.085 | 2.869 |
表2报告了主要变量的描述性统计结果,包括样本量、均值、标准差、最小值、中位数、最大值。 本研究最终样本包含 960 个观测值。样本已执行去重与变量质量检查;如流程启用自动清洗,连续变量会按审计记录进行 1% 双侧 Winsor 缩尾,虚拟变量、低离散计数变量等不适合缩尾的变量会被跳过。 作为被解释变量的结果变量,其样本均值为 0.277,中位数为 0.269,标准差为 0.832,最小值与最大值分别为 -2.296 和 2.874;变异系数大于 1,个体间差异显著。 作为核心解释变量的处理变量,其样本均值为 -0.011,中位数为 0.031,标准差为 0.955,最小值与最大值分别为 -3.482 和 3.014;变异系数大于 1,个体间差异显著。 在控制变量方面,主要控制变量的描述性统计如下:ctrl1(均值 -0.013,标准差 1.022,区间 [-3.004, 3.081]);ctrl2(均值 0.080,标准差 1.000,区间 [-2.945, 2.869])。整体上,控制变量的取值分布未显示出影响后续估计的明显极端异常。 被解释变量与核心解释变量均存在可用于估计的样本内变异(σ(dv)=0.832,σ(iv)=0.9553),为后续回归识别核心系数提供了必要的统计基础。
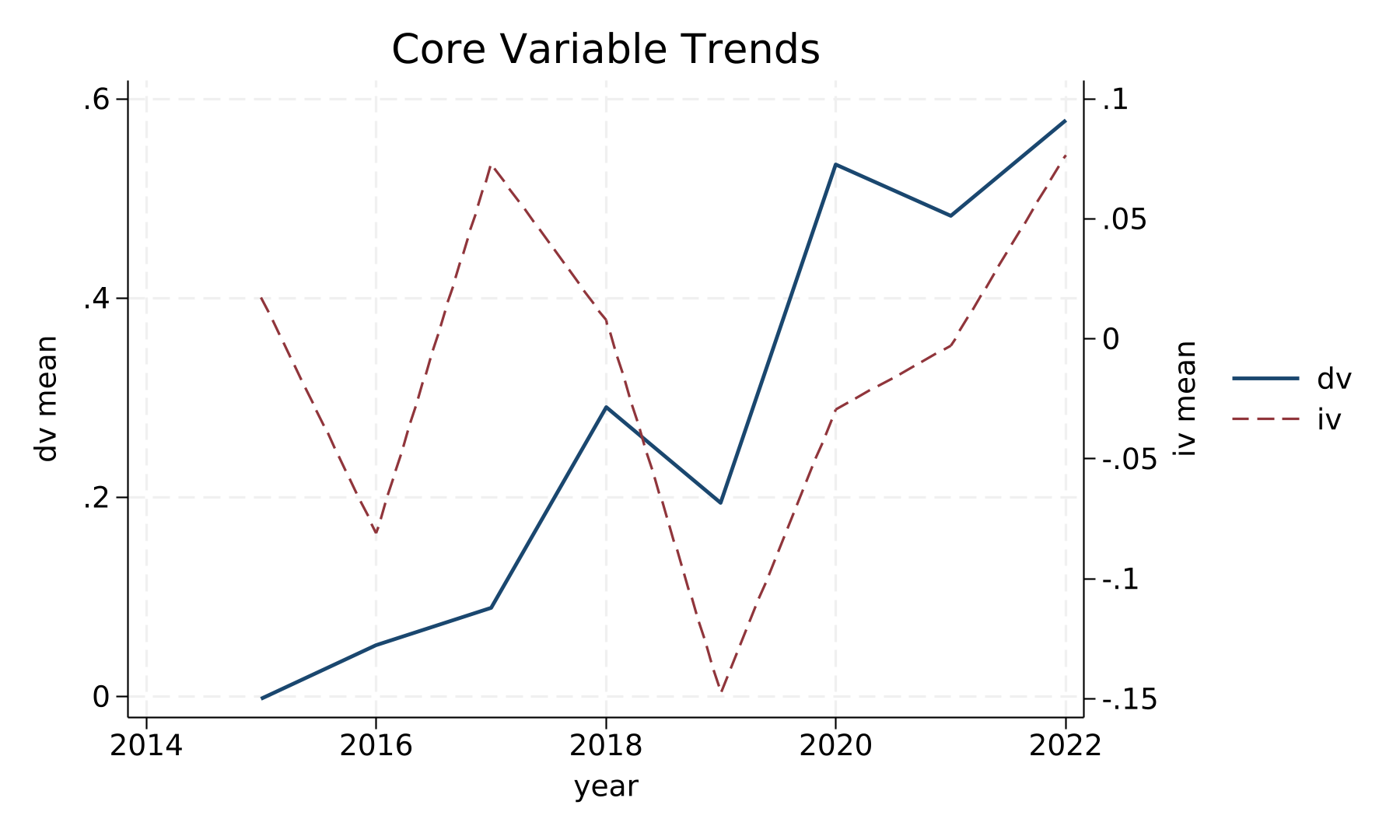
图1 核心变量时序趋势
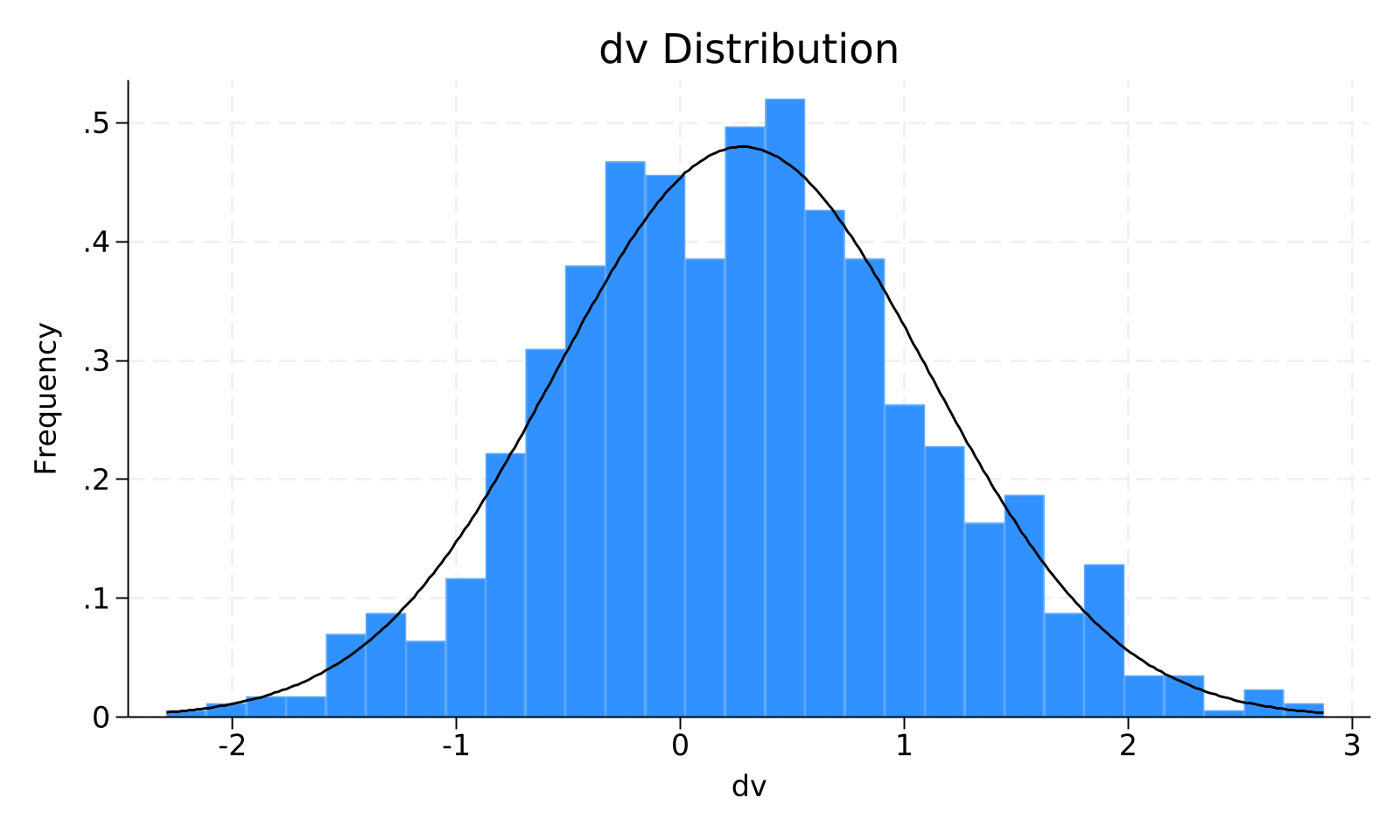
图2 dv 分布直方图
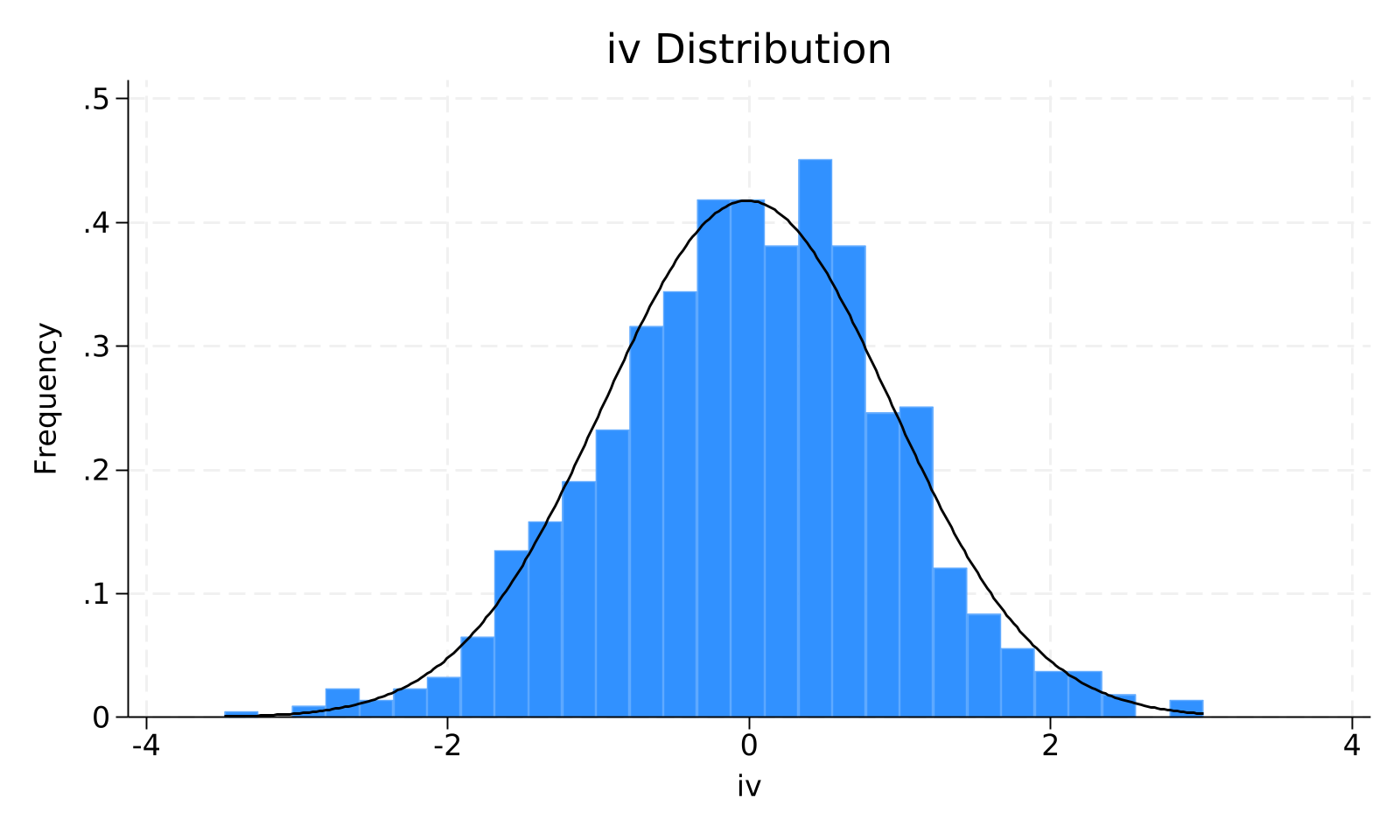
图3 iv 分布直方图
二、相关性分析
| dv | iv | m | ctrl1 | ctrl2 | |
|---|---|---|---|---|---|
| dv | 1.000 | <0.001 | <0.001 | <0.001 | <0.001 |
| iv | 0.681*** | 1.000 | <0.001 | 0.837 | 0.734 |
| m | 0.650*** | 0.890*** | 1.000 | 0.146 | 0.581 |
| ctrl1 | 0.260*** | 0.007 | 0.047 | 1.000 | 0.427 |
| ctrl2 | 0.129*** | -0.011 | -0.018 | 0.026 | 1.000 |
注:下三角为 Pearson 相关系数;右上角为双侧 p 值;* / ** / *** 分别表示 10% / 5% / 1% 水平显著。
表3报告了主要变量间的 Pearson 相关系数矩阵,括号中 p 值基于双侧 t 检验。 核心解释变量处理变量与被解释变量结果变量的相关系数为 0.681(p<0.001),呈正相关,在 1% 水平上显著,为后续回归中的系数方向提供了一致的初步证据。 控制变量之间相关性排序(按绝对值)前三分别为:中介机制与处理变量为 0.890(p<0.001);ctrl1与中介机制为 0.047(p=0.146);ctrl2与ctrl1为 0.026(p=0.427)。 其中最高相关绝对值达到 0.890,已超过 0.7 的经验阈值,后续回归中须结合 VIF 或逐步加入控制变量的方式排查多重共线性;必要时可剔除其一或合成为因子变量。 整体上,10 对两两相关中有 5 对在 5% 水平上显著(占 50.0%),反映变量之间存在实质性的统计关联,为后续多元回归提供了充足的共变异基础。
三、多重共线性检验
为排查解释变量之间的多重共线性,本文对基准回归纳入的核心解释变量与控制变量逐一估计方差膨胀因子(VIF),结果见表4。全部 3 个变量中,最大 VIF 为 1.001(ctrl1),均值为 1.001,严重共线(VIF>10)变量 0 个,需要关注(5<VIF≤10)变量 0 个。按照 Greene (2018) 的经验判据,VIF 低于 10 即可认为多重共线性对系数估计不构成实质性威胁,低于 5 则可放心使用。
| 变量 | VIF | 1/VIF | 判定 |
|---|---|---|---|
| iv | 1.000 | 1.000 | 可接受 |
| ctrl1 | 1.001 | 0.999 | 可接受 |
| ctrl2 | 1.001 | 0.999 | 可接受 |
注:VIF>10 视为严重共线性,5–10 需关注,<5 可接受。
综合来看,全部变量 VIF 均处于 5 以下(最大值 1.001,均值 1.001),多重共线性风险可忽略,基准回归系数估计的稳定性与可解释性不会受到显著影响。
四、Hausman 检验
为判定面板数据回归中应采用固定效应(FE)还是随机效应(RE)模型,本文进行豪斯曼检验,原假设 H0 为『个体效应与解释变量不相关』(即 RE 估计量一致且更有效)。结果见表5。检验统计量 Chi² = 0.6501(df = 3),p 值 = 0.8849,未能拒绝原假设;考虑到面板回归中个体异质性的普遍存在,本文仍以固定效应作为主设定,并在稳健性环节给出 RE 对照。
| 统计量 | 值 |
|---|---|
| Chi2 | 0.6501 |
| df | 3 |
| p-value | 0.8849 |
| 结论 | 不拒绝原假设,使用随机效应模型 (RE) |
注:H0 = 个体效应与解释变量无关;p<0.05 拒绝 H0,应使用固定效应。
出于稳健性与可比性考虑,本文仍沿用固定效应作为主设定,并在必要时报告随机效应估计结果作为交叉验证。
五、模型设定与基准回归结果
为检验处理变量对结果变量的影响,本文构建如下基准回归模型:
Yit = α + β1 Tit + γControlsit + μi + λt + εit
其中,下标 i 和 t 分别表示个体和时间。Y_it 为被解释变量(结果变量);T_it 为核心解释变量(处理变量),其系数 β_1 是本文关注的核心参数。Controls_it 包括ctrl1、ctrl2。μ_i 为个体固定效应,用于控制不随时间变化的异质性。λ_t 为时间固定效应,用于控制宏观时间趋势。ε_it 为随机扰动项。为缓解异方差,本文采用聚类稳健标准误。
| 变量 | (1) OLS | (2) OLS + Controls | (3) 个体固定效应 | (4) 个体固定效应 + 时间固定效应 |
|---|---|---|---|---|
| iv | 0.5925*** | 0.5922*** | 0.5893*** | 0.5879*** |
| (0.0210) | (0.0192) | (0.0187) | (0.0167) | |
| ctrl1 | 0.2050*** | 0.1995*** | 0.2064*** | |
| (0.0184) | (0.0191) | (0.0176) | ||
| ctrl2 | 0.1079*** | 0.1108*** | 0.1205*** | |
| (0.0185) | (0.0177) | (0.0167) | ||
| 核心解释变量口径 | iv | iv | iv | iv |
| 估计模型 | OLS/FE | OLS/FE | OLS/FE | OLS/FE |
| 控制变量 | 否 | 是 | 是 | 是 |
| 个体固定效应 | 否 | 否 | 是 | 是 |
| 时间固定效应 | 否 | 否 | 否 | 是 |
| 聚类标准误 | 稳健标准误 | 稳健标准误 | 稳健标准误 | 稳健标准误 |
| N | 960 | 960 | 960 | 960 |
| R² | 0.4632 | 0.5452 | 0.6388 | 0.7090 |
注:括号内为标准误。采用异方差稳健(HC1)标准误,未做聚类。已吸收 个体FE、时间FE。***、**、* 分别表示 1%、5%、10% 显著性水平。
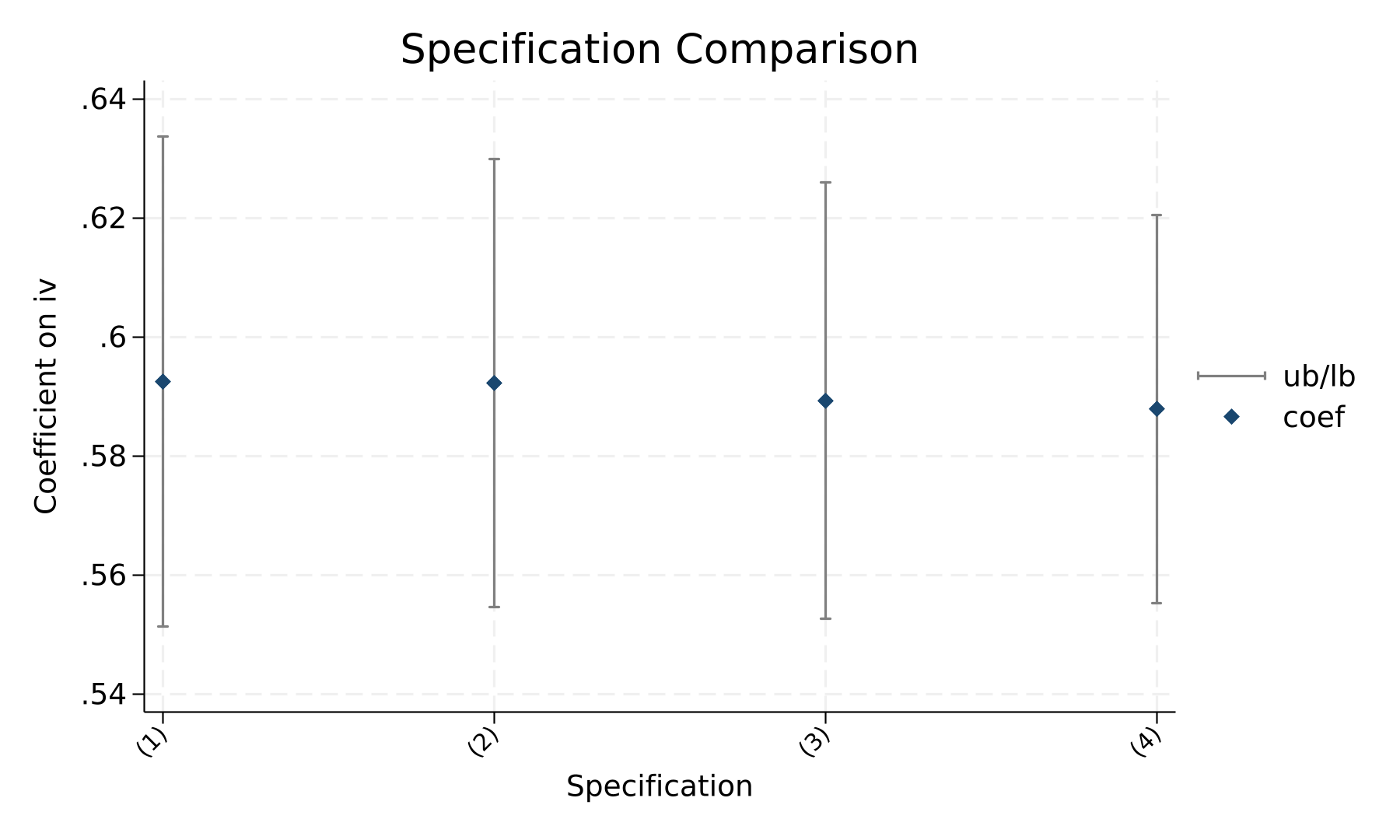
图4 基准回归系数对比
表6报告了处理变量影响结果变量的基准回归结果。表6第(1)列为未加入控制变量和固定效应的OLS估计,处理变量的系数为0.5925,标准误为0.0210,并在1%水平上显著。这表明,在最简模型中,处理变量与结果变量之间存在显著正向关系,即处理变量每增加1个单位,结果变量平均提高0.5925个单位。该结果为本文提出的正向影响假设提供了初步证据,但由于该列尚未控制其他可观测因素和不可观测个体差异,因此仍需进一步检验系数稳定性。表6第(2)列在第(1)列基础上加入C1和C2。结果显示,处理变量的系数为0.5922,标准误为0.0192,仍在1%水平显著。与第(1)列相比,处理变量的系数仅下降0.0003,说明加入控制变量后核心估计并未发生明显变化。与此同时,C1的系数为0.2050,标准误为0.0184,C2的系数为0.1079,标准误为0.0185,二者均在1%水平显著,说明控制变量对结果变量具有独立解释力,也表明将其纳入模型具有必要性。表6第(3)列进一步控制个体固定效应,以排除不随时间变化的个体特征对估计结果的干扰。结果显示,处理变量的系数为0.5893,标准误为0.0187,仍在1%水平显著。相较第(2)列,核心系数略有下降,但仍保持正向且显著,说明处理变量对结果变量的影响并非主要由个体层面固定差异所驱动。第(3)列中,C1的系数为0.1995,标准误为0.0191;C2的系数为0.1108,标准误为0.0177,均在1%水平显著。表6第(4)列同时控制个体固定效应和时间固定效应,是本文的主基准模型。结果显示,处理变量的系数为0.5879,标准误为0.0167,并在1%水平显著;样本量为960,R²为0.7090。该结果意味着,在控制C1、C2以及个体和时间层面不可观测因素后,处理变量每增加1个单位,结果变量平均增加0.5879个单位。比较表6四列结果可以发现,处理变量的系数始终稳定在0.5879至0.5925之间,方向一致且显著性水平一致,说明基准结论具有较强稳定性。进一步从经济显著性看,处理变量的标准差为0.9553,结果变量的标准差为0.8315。经济显著性检验显示,标准化β=0.6754,表明处理变量增加1个标准差将带来结果变量约0.6754个标准差的提升。换算为原始量纲,处理变量增加1个标准差对应结果变量提高约0.5616个单位。考虑到结果变量的样本标准差为0.8315,这一影响幅度在经济意义上较为可观,并非仅是统计意义上的微弱相关。因此,表6的基准结果不仅支持处理变量对结果变量的显著正向影响,也说明这种影响具有较强实际解释力。
六、稳健性检验
| 变量 | (R1) 双重聚类(个体+时间) | (R2) 1% Winsor | (R3) 5% Winsor | (R4) 剔除异常残差 |rstudent|>3 |
|---|---|---|---|---|
| iv | 0.5879*** | 0.5866*** | 0.5860*** | 0.5879*** |
| (0.0257) | (0.0165) | (0.0170) | (0.0167) | |
| ctrl1 | 0.2064*** | 0.1997*** | 0.1795*** | 0.2064*** |
| (0.0184) | (0.0172) | (0.0163) | (0.0176) | |
| ctrl2 | 0.1205*** | 0.1197*** | 0.1108*** | 0.1205*** |
| (0.0240) | (0.0164) | (0.0156) | (0.0167) | |
| 核心解释变量口径 | iv | iv | iv | iv |
| 估计模型 | OLS/FE | OLS/FE | OLS/FE | OLS/FE |
| 控制变量 | 是 | 是 | 是 | 是 |
| 个体固定效应 | 是 | 是 | 是 | 是 |
| 时间固定效应 | 是 | 是 | 是 | 是 |
| 聚类标准误 | 双重聚类(个体+时间) | 稳健标准误 | 稳健标准误 | 稳健标准误 |
| N | 960 | 960 | 960 | 960 |
| R² | 0.7090 | 0.7072 | 0.6929 | 0.7090 |
注:括号内为标准误;稳健性表与基准回归表保持同构。标准误聚类至 双重聚类(个体+时间) 层级。已吸收 个体FE、时间FE。***、**、* 分别表示 1%、5%、10% 显著性水平。
表7报告了稳健性检验结果。首先,为避免同一主体内部相关和同一时期共同冲击导致标准误低估,表7第(R1)列采用个体和时间双重聚类标准误。结果显示,处理变量的系数为0.5879,标准误为0.0257,并在1%水平显著,说明核心结论并不依赖于常规稳健标准误设定。其次,为排除极端值对估计结果的影响,表7第(R2)列和第(R3)列分别采用1%和5% Winsor处理,处理变量的系数分别为0.5866和0.5860,标准误分别为0.0165和0.0170,均在1%水平显著,表明异常极端取值并未驱动基准结果。再次,表7第(R4)列剔除异常残差|rstudent|>3的观测,处理变量的系数仍为0.5879,标准误为0.0167,并在1%水平显著。最后,安慰剂检验通过500次随机化置换处理变量,真实核心解释变量系数为0.5879,打乱后|系数|≥真实|系数|的次数为0,经验p值=0。上述结果共同说明,本文核心结论在不同标准误处理、异常值处理和随机化检验下均保持稳健。
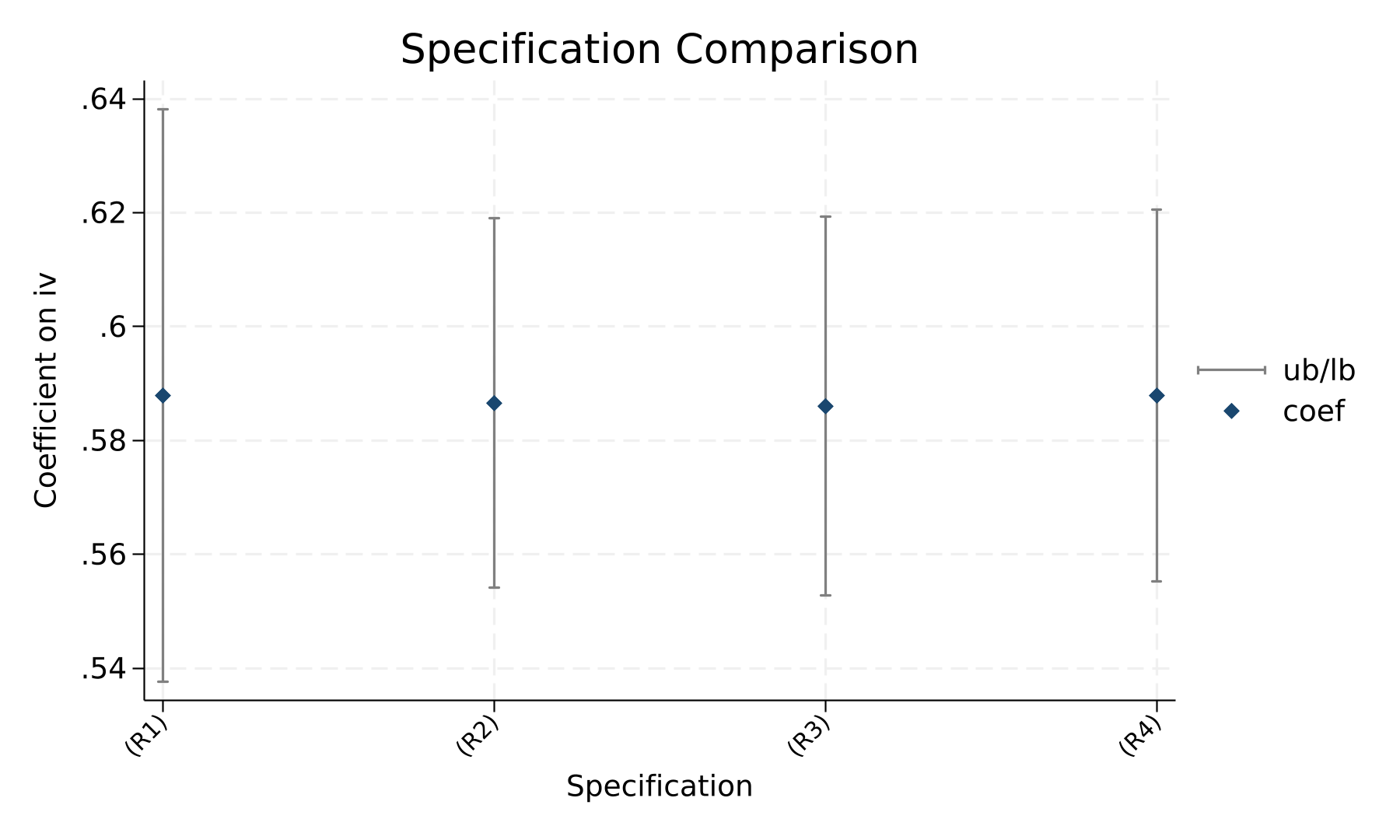
图5 稳健性系数对比
七、异质性分析
| 变量 | (subgroup=0) | (subgroup=1) |
|---|---|---|
| iv | 0.5919*** | 0.5950*** |
| (0.0253) | (0.0234) | |
| ctrl1 | 0.1734*** | 0.2218*** |
| (0.0251) | (0.0232) | |
| ctrl2 | 0.0874*** | 0.1265*** |
| (0.0237) | (0.0241) | |
| N | 384 | 576 |
| R² | 0.6401 | 0.6283 |
注:括号内为标准误。***、**、* 分别表示 1%、5%、10% 显著性水平。⚠ 各列样本量在 384–576 之间不完全一致,说明列间因控制变量缺失而存在样本差异;解读列间系数比较时需考虑该差异。
表8基于G进行分组回归,以考察处理变量对结果变量的影响是否随分组属性不同而存在差异。分组检验的经济直觉在于,不同主体可能面临不同资源条件、行为约束或环境特征,因而同一处理因素的边际作用可能存在差别。如果某一组具有更强吸收能力或更高处理强度转化效率,则处理变量对结果变量的影响可能更强。表8第(G=0)列显示,处理变量的系数为0.5919,标准误为0.0253,并在1%水平显著;C1和C2的系数分别为0.1734和0.0874,均在1%水平显著。表8第(G=1)列显示,处理变量的系数为0.5950,标准误为0.0234,同样在1%水平显著;C1和C2的系数分别为0.2218和0.1265,也均在1%水平显著。上述结果说明,在两个分组内部,处理变量对结果变量均具有稳定的正向影响。但需要强调的是,是否存在显著异质性不能仅凭两组系数大小判断。组间系数差异检验(Chow交互项法):组间系数差 = 0.0072,标准误 = 0.0375,p = 0.848,在常规显著性水平上不显著。因此,虽然两组系数均统计显著,但组间差异检验未拒绝H0,不能断言某组效应强于另一组。更审慎的结论是,处理变量对结果变量的正向作用在不同G分组中均存在,但现有证据不支持显著组间差异。
八、中介效应检验
| 路径 | 系数 | 标准误 | 说明 |
|---|---|---|---|
| c (总效应 iv->dv) | 0.5879 | 0.0158 | p<0.001 |
| a (路径 iv->m) | 0.5985 | 0.0085 | p<0.001 |
| b (路径 m->dv|控 iv) | 0.2430 | 0.0524 | p<0.001 |
| c' (直接效应) | 0.4424 | 0.0344 | p<0.001 |
| a*b (间接效应) | 0.1455 | 0.0314 | Sobel Z= 4.6256; p<0.001 |
注:数据来源于 Stata 对本样本的实际估计输出。
表9报告了M的中介效应检验结果。理论上,处理变量可能并非完全直接影响结果变量,而是通过改善中间过程、提高传导效率或增强主体能力等方式间接发挥作用。因此,M被设定为连接处理变量与结果变量之间关系的机制变量,用于检验处理变量是否通过该机制进一步影响结果变量。中介效应采用Bootstrap percentile方法进行检验,重复抽样次数为500次。结果显示,间接效应为0.1307,标准误为0.0316,95%置信区间下限为0.0686,上限为0.1869。由于该置信区间不包含0,说明处理变量通过M影响结果变量的间接效应在统计上显著。该结果支持M在处理变量影响结果变量过程中发挥中介作用,即处理变量的一部分影响可以通过M这一机制传导至结果变量。需要注意的是,相关分析显示M与处理变量之间相关系数较高,达到0.890,因此在解释中介机制时应避免将其表述为完全独立的因果通道。更稳妥的写法是,现有Bootstrap结果支持M具有显著传导作用,但未来仍需通过替代性机制变量或更细致的测度方式进一步验证该机制是否存在概念重叠或共线性问题。
九、内生性处理
| 统计量 | 值 |
|---|---|
| 状态 | ok |
| 系数(2SLS) | 0.5604 |
| 标准误 | 0.0224 |
| z/t 统计量 | 24.9684 |
| p 值 | <0.001 |
| N | 960 |
| R² | 0.6143 |
| 第一阶段 F (弱工具) | 993.2512 |
| 第一阶段 F 来源 | absorbed-FE first-stage joint test |
| Stock-Yogo 10%临界值 | 16.38 |
| 弱工具判定 | 工具强度通过 Stock-Yogo 10% 临界值 |
| 过度识别检验 p | n/a(恰好识别) |
| Kleibergen-Paap LM | n/a |
| Kleibergen-Paap LM p | n/a |
| Anderson-Rubin chi2 | n/a(weakivtest 未运行) |
| Anderson-Rubin p | n/a |
| Wu-Hausman 内生性 p | n/a(estat endogenous 未运行) |
| 工具变量 | z |
注:数据来源于 Stata 对本样本的实际估计输出。
表8采用工具变量Z进行2SLS估计,以缓解T与Y之间可能存在的内生性问题。内生性可能来源于三个方面:一是反向因果,即Y较高的主体可能更容易形成更高水平的T;二是遗漏变量,即某些未观测因素可能同时影响T和Y;三是测量误差,即T的代理变量可能无法完全反映真实处理强度。若不处理这些问题,基准固定效应估计可能存在偏误。工具变量估计结果显示,第一阶段F统计量为993.2512,且高于Stock-Yogo 10%临界值16.38,弱工具变量判定为通过。这说明Z与T之间具有较强相关性,工具变量强度较好。由于当前模型为恰好识别,过度识别检验p值为n/a,Kleibergen-Paap LM和Anderson-Rubin检验亦未提供有效结果。因此,Z的外生性仍需主要依赖理论层面的排他性约束论证,即Z应仅通过影响T进而影响Y,而不应直接影响Y。第二阶段结果显示,T的2SLS系数为0.5604,标准误为0.0224,Z/t统计量为24.9684,p值为0.000,样本量为960,R²为0.6143。与表6第(4)列固定效应估计系数0.5879相比,IV估计系数略有下降,说明OLS或固定效应估计可能存在一定向上偏误。但2SLS系数仍为正且高度显著,表明在缓解内生性担忧后,T对Y的正向影响依然成立。
本文实施 2SLS 工具变量估计以缓解内生性:二阶段核心系数 = 0.5604(标准误 0.0224,p = 0.0000),第一阶段 F 统计量 = 993.2512(来源:absorbed-FE first-stage joint test),N = 960。从诊断统计量看,工具变量强度基本充足;二阶段系数方向为正向,在 1% 水平上显著。由于工具变量法假设工具变量仅通过内生变量影响 DV,本文在变量定义与识别假设处已明确此外生性假设的经济学依据。
十、双重差分检验
| 指标 | 值 |
|---|---|
| 状态 | ok |
| DID项 | treat × post |
| 模型 | TWFE: entity FE + time FE |
| 系数 | 0.8625 |
| 标准误 | 0.0886 |
| t/z统计量 | 9.7399 |
| p值 | <0.001 |
| N | 960 |
| R² | 0.3853 |
注:数据来源于 Stata 对本样本的实际估计输出。
DID 检验已经生成可解析输出,以下叙述依据对应 CSV/表格回填。
状态=ok; DID项=D × Post; 模型=TWFE: entity FE + tiMe FE; 系数=0.8625; 标准误=0.0886; p值=0.0000; N=960; R²=0.3853
平行趋势诊断:状态=declaredEventTiMe; EventTiMevar=EventTiMe; 说明=已识别相对事件时间变量;下方 lead/lag 事件研究系数已落入 eventstudy_coefficients.csv。
事件研究 lead/lag 系数(事前显著 lead 系数:-5,-4,-3,-2,-1 — 平行趋势警告):k=-5: coef=-1.2933 se=0.1778 p=<1e-9; k=-4: coef=-1.0281 se=0.1784 p=6.6e-08; k=-3: coef=-1.0768 se=0.1488 p=<1e-9; k=-2: coef=-0.8001 se=0.1109 p=<1e-9; k=-1: coef=-1.1092 se=0.1399 p=<1e-9; k=1: coef=-0.2147 se=0.1345 p=0.113; k=2: coef=-0.1865 se=0.1285 p=0.149; k=3: coef=0.1141 se=0.1729 p=0.510; k=4: coef=-0.0380 se=0.1797 p=0.833
安慰剂检验 (n=500, 均值=0.3318); 真实系数=0.8625; |安慰剂|≥|真实| 次数=0/500; 经验p=0.0000
该部分应作为扩展证据或诊断证据使用,正式论文中需要结合样本量、模型前提和诊断统计量判断其解释强度。
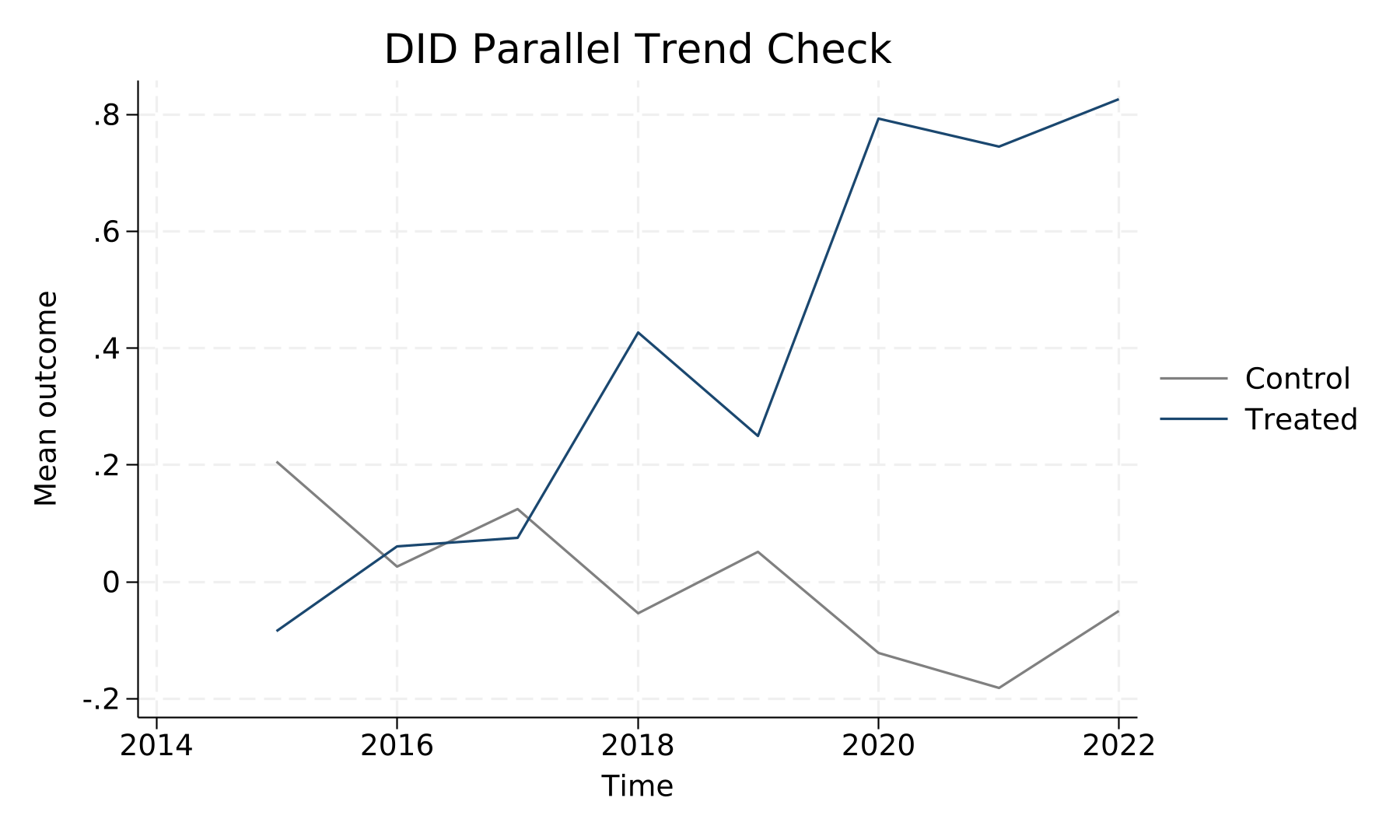
图6 平行趋势检验
为正式检验政策冲击的动态效应与平行趋势假设,本文以 event_time = 0 作为基期,估计 [-5, +5] 窗口内 lead/lag 系数(共 11 个相对时点;其中 5 个 lead、5 个 lag)。完整的系数、聚类标准误及 95% 置信区间见表12。理想情况下事件前各 lead 系数应统计上不显著(支持平行趋势),事件后 lag 系数表现处理效应的动态轨迹。
| k | coef | se | t | pvalue | ci_lo | ci_hi |
|---|---|---|---|---|---|---|
| -5 | -1.2933 | 0.1778 | -7.2742 | 4.03e-11 | -1.6418 | -0.9449 |
| -4 | -1.0281 | 0.1784 | -5.7645 | 6.58e-08 | -1.3777 | -0.6786 |
| -3 | -1.0768 | 0.1488 | -7.2375 | 4.86e-11 | -1.3684 | -0.7852 |
| -2 | -0.8001 | 0.1109 | -7.2125 | 5.53e-11 | -1.0175 | -0.5827 |
| -1 | -1.1092 | 0.1399 | -7.9273 | 1.35e-12 | -1.3834 | -0.8349 |
| 0 | baseline (omitted) | — | — | — | — | — |
| 1 | -0.2147 | 0.1345 | -1.5969 | 0.1129 | -0.4782 | 0.0488 |
| 2 | -0.1865 | 0.1285 | -1.4510 | 0.1494 | -0.4384 | 0.0654 |
| 3 | 0.1141 | 0.1729 | 0.6601 | 0.5105 | -0.2247 | 0.4529 |
| 4 | -0.0380 | 0.1797 | -0.2117 | 0.8327 | -0.3902 | 0.3141 |
| 5 | (no observations) | — | — | — | — | — |
注:event_time = 0 为基期被省略;标准误聚类至个体;95% CI 取 ±1.96·SE。
事件前共有 5 个 lead 系数在 5% 水平显著(k=[-5, -4, -3, -2, -1]),提示平行趋势可能存在张弛,应在稳健性中进一步检验。⚠ 多个 pre-treatment lead 同时显著是交错 DID(staggered treatment)下 TWFE 估计的典型偏误信号(参见 Goodman-Bacon 2021)。建议补做 Sun & Abraham (2021) 的 eventstudyinteract、Callaway & Sant'Anna (2021) 的 csdid,或 de Chaisemartin & d'Haultfœuille (2020) 的 did_multiplegt 等异质性 DID 估计,比较 ATT(g, t) 与当前 TWFE 系数的差距。事件后 lag 系数均值约 -0.0813,动态轨迹见 event_study_plot.png。
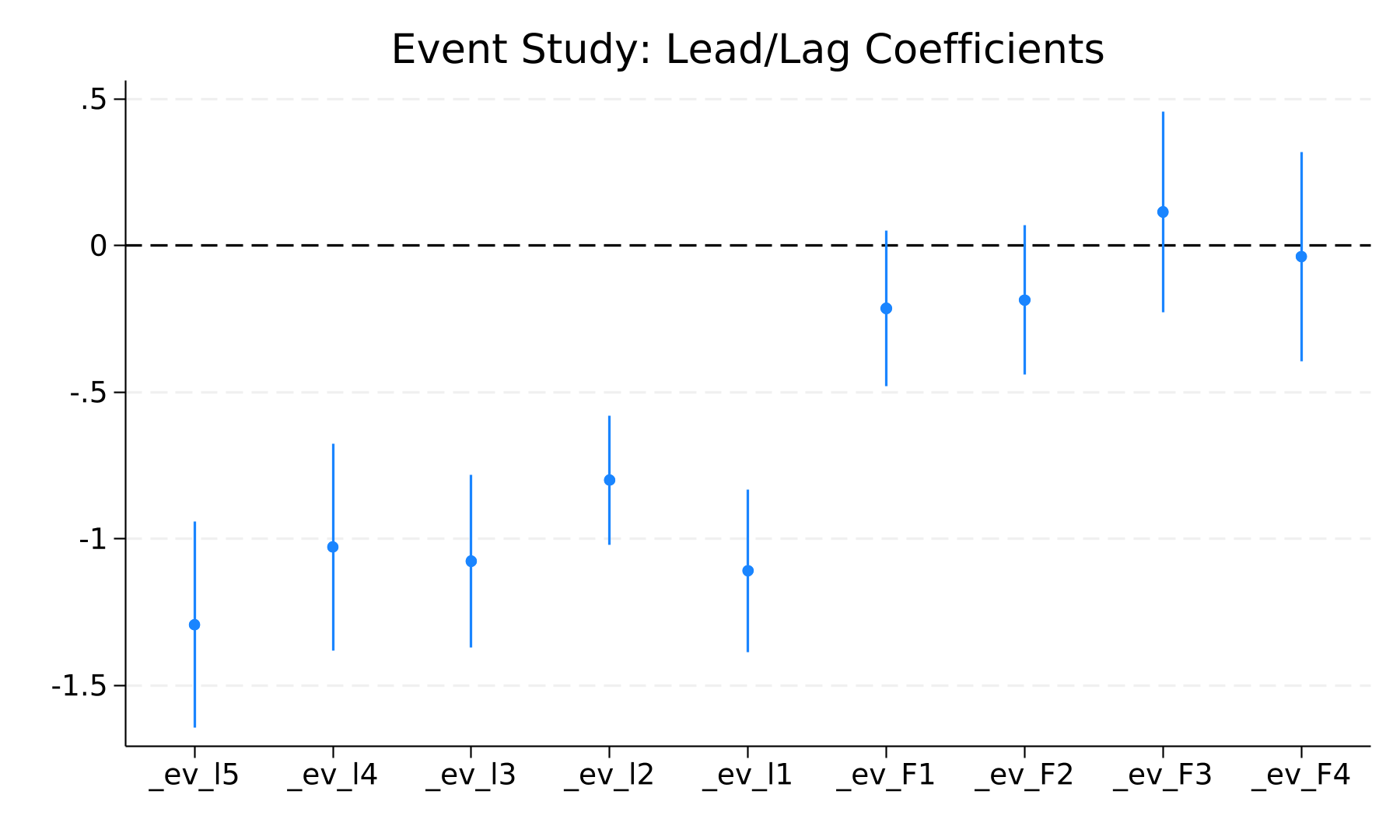
图7 事件研究图
为排除其他不可观测冲击在样本期内系统性影响处理组与对照组的可能,本文执行 500 次随机化安慰剂检验:每次随机重抽 fake-treatment 分配并重估同一 DID 设定,得到伪处理系数的经验分布。真实 DID 系数 = 0.8625,安慰剂分布中绝对值不小于该值的次数为 0/500,经验 p 值 ≈ 0.000。详细分布见表13 与 did_placebo_distribution.png。
| 统计量 | 值 |
|---|---|
| 迭代次数 | 500 |
| 真实 DID 系数 | 0.8625 |
| 安慰剂分布均值 | 0.3318 |
| 安慰剂分布中位数 | 0.3333 |
| 5% 分位数 | 0.2230 |
| 95% 分位数 | 0.4457 |
| |安慰剂| ≥ |真实| 次数 | 0 |
| 经验 p 值 | 0.0000 |
注:安慰剂检验通过随机重抽处理分配(保持时间结构不变)多次复估同一 DID 设定。经验 p 值 < 0.05 表示真实 DID 系数显著偏离随机分布尾部,支持因果识别。
十一、高标准诊断边界
按优秀硕士论文工作稿标准,本报告已提供可复核的表格、图形和诊断输出;若进一步以优秀博士生或规范期刊论文标准衡量,当前版本仍需把识别一致性、变量口径稳定性和扩展检验有效性作为主要边界。 当前系统判定为“建议补充后投稿”。 量化成熟度评分为 19。
主要边界如下:
(1)异质性分组虽已实施,但组间差异证据偏弱,扩展结论说服力有限。
(2)复现材料仍不够完整,工程规范优势尚未完全建立。
建议优先补强:
(1)在异质性部分明确写出组间差异不显著,避免夸大分组结论。
(2)重新审查中介变量m与处理变量iv是否存在定义重叠,必要时更换中介变量或补充替代机制检验。
(3)优先补充每个变量的真实经济含义、计算方式、数据来源和理论依据。